Large language models (LLMs) are remarkably capable—but they often stumble when applied to specialized domains like finance, legal, healthcare, or engineering. Why? Because they lack exposure to high-quality, structured training data from those fields. Creating such data manually is tedious, inconsistent, and doesn’t scale.
Enter Easy Dataset: an open-source, GUI-driven application that automates the entire pipeline for transforming unstructured documents—PDFs, DOCX files, Markdown notes, and more—into polished, ready-to-use fine-tuning datasets. What sets it apart is its human-in-the-loop design: the system handles the heavy lifting, while you retain full control to review, edit, and refine every step. No coding required, yet powerful enough for expert teams.
Why Domain-Specific Fine-Tuning Fails Without the Right Data
Fine-tuning an LLM on generic datasets won’t teach it how to interpret a clinical trial report or explain a tax regulation. You need relevant, accurate, and well-structured examples—ideally in a question-answer format with clear reasoning. Most teams either skip this step (and accept poor performance) or spend weeks hand-crafting datasets.
Easy Dataset solves this by turning your existing knowledge assets—internal wikis, research papers, product manuals—into structured training data in hours, not weeks.
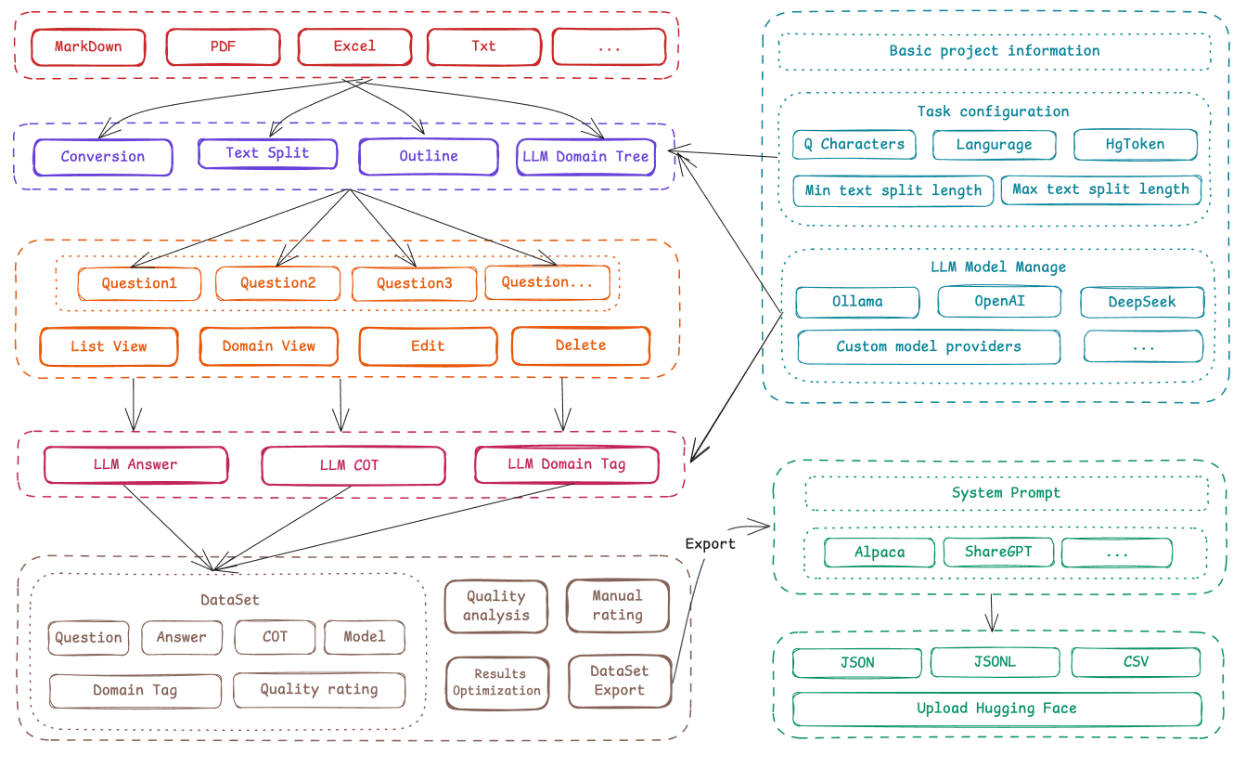
How It Works: A Visual, Step-by-Step Workflow
The process is designed for clarity and flexibility:
- Create a project and connect your preferred LLM API (any OpenAI-compatible service, including Ollama, OpenRouter, or self-hosted models).
- Upload documents in supported formats: PDF, DOCX, Markdown, or plain text.
- Review auto-split text chunks—the system intelligently segments content while preserving context, and you can adjust boundaries visually.
- Generate questions automatically from each segment. These aren’t random—they’re derived using persona-driven prompts to reflect real user inquiries.
- Generate answers using your configured LLM, complete with Chain-of-Thought reasoning for richer training signals.
- Edit anything at any stage: fix a mis-split paragraph, rewrite a vague question, or polish an answer.
- Export in standard formats like Alpaca, ShareGPT, or multilingual-thinking, as JSON or JSONL—ready for LLaMA Factory, Hugging Face, or your custom trainer.
This end-to-end control ensures your dataset is both scalable and trustworthy.
Key Features That Deliver Real-World Value
- Multi-format document intelligence: Handles complex layouts in PDFs and structured content in DOCX with robust parsing.
- Smart chunking with visual feedback: Avoids arbitrary cuts that break meaning—ideal for technical or legal text.
- Domain-aware labeling: Automatically builds a global domain taxonomy, helping maintain consistency across large datasets.
- Custom system prompts: Inject domain-specific instructions (e.g., “You are a financial analyst…”) to steer generation quality.
- Offline-first, local data: All processing happens on your machine—no documents leave your environment unless you choose to.
Deployment Flexibility: Desktop, CLI, or Docker
Easy Dataset meets you where you are:
- Desktop apps for Windows, macOS (Intel and Apple Silicon), and Linux—just download and run.
- Local development via npm for those who prefer source control and customization.
- Docker or docker-compose for team deployments, CI pipelines, or server-based usage.
All options preserve full data ownership and privacy.
Practical Limitations to Consider
While powerful, Easy Dataset has realistic boundaries:
- It requires an LLM API for question and answer generation—meaning you’ll need access to a model (open or commercial).
- Scanned or image-based PDFs won’t work well unless pre-OCR’d, as the tool relies on extractable text.
- The AGPL 3.0 license allows free use and modification, but derivative commercial products must open-source their changes.
- Very large document collections may benefit from batch processing rather than uploading all at once.
These aren’t blockers—they’re clear trade-offs that empower informed decisions.
Proven Impact and Growing Adoption
Easy Dataset isn’t just a prototype. Peer-reviewed experiments show that models fine-tuned on its synthesized data significantly outperform baselines on domain-specific tasks like financial QA—without losing general knowledge.
With over 9,000 GitHub stars, tight integration with tools like LLaMA Factory, and active community guides, it’s rapidly becoming a go-to solution for teams serious about domain adaptation.
Summary
Easy Dataset removes the biggest roadblock to effective LLM fine-tuning: the lack of high-quality, domain-specific training data. By combining automated generation with intuitive human oversight, it delivers a rare balance of speed, quality, and control.
Whether you’re a startup building a vertical chatbot, a researcher adapting models to scientific literature, or an enterprise team creating an internal knowledge assistant, Easy Dataset turns your unstructured documents into a strategic AI asset—visually, efficiently, and reliably.