If you’re building or fine-tuning large language models (LLMs) for reasoning—whether in math, coding, search, or agentic workflows—you’ve likely hit a wall with traditional reinforcement learning (RL) pipelines. Most RL systems for LLMs operate synchronously: a batch of model rollouts is generated, then training pauses until the slowest output finishes. This creates massive GPU idle time and slows down iteration cycles, especially when scaling to hundreds or thousands of GPUs.
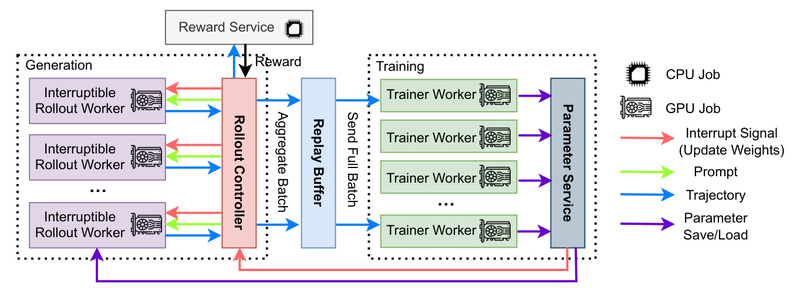
Enter AReaL: an open-source, fully asynchronous reinforcement learning system purpose-built for training reasoning-focused LLMs and AI agents at scale. By decoupling rollout generation from model training, AReaL eliminates GPU underutilization and achieves up to 2.77× faster training compared to synchronous alternatives—without sacrificing final model performance. Developed by the AReaL Team at Ant Group and built on the ReaLHF foundation, AReaL is designed for researchers and engineers who need speed, stability, and flexibility in large-scale RL workflows.
Why Traditional Synchronous RL Falls Short
In standard synchronous RL setups for LLMs, all samples in a training batch must be generated by the same model version before any gradient update can occur. This “stop-and-wait” behavior means GPUs sit idle while waiting for the slowest sequence (e.g., a long code generation or multi-step reasoning trace) to complete—even if other rollouts are ready. As batch sizes grow and tasks become more complex, this inefficiency compounds, making large-scale experiments prohibitively slow and costly.
AReaL tackles this head-on by embracing full asynchronicity: rollout workers continuously produce new data using the latest (or slightly stale) model checkpoints, while training workers consume incoming data as soon as enough samples are available. There’s no enforced synchronization. This design dramatically improves hardware utilization and enables smoother scaling across heterogeneous clusters.
Core Innovations That Make AReaL Work
Decoupled Rollout and Training Pipelines
AReaL’s architecture separates data generation from optimization. Rollout workers run inference continuously—often leveraging high-performance backends like vLLM or SGLang—while training workers pull batches from a shared buffer. This allows each component to operate at its natural pace, maximizing throughput.
Staleness-Aware Training Stability
Asynchronicity introduces a challenge: training data may be generated by older model versions (“stale” rollouts). To ensure stable convergence, AReaL balances the ratio of rollout to training workers and implements a staleness-enhanced PPO variant that gracefully handles outdated samples. Empirical results on math and code benchmarks confirm that this approach matches or exceeds the final performance of synchronous baselines.
Algorithm and Infrastructure Co-Design
AReaL isn’t just a system—it’s a co-designed stack. It supports a wide array of RL algorithms optimized for reasoning tasks, including GRPO, GSPO, DAPO, LitePPO, and Dr.GRPO, all configurable via simple YAML files. The system integrates seamlessly with modern training backends like PyTorch FSDP and Megatron, and supports LoRA, MoE models, and vision-language variants like Qwen2.5-VL.
Practical Flexibility: AReaL-lite for Researchers
Recognizing that not every user needs enterprise-scale deployment, the team introduced AReaL-lite: a lightweight, algorithm-first version with 80% less code but 90% of AReaL’s core functionality. AReaL-lite is ideal for rapid prototyping, academic research, or small-team experimentation. It retains full asynchronous RL support while offering an intuitive API for customizing reward functions, multi-turn agent workflows, and dataset pipelines—all in a single file.
Ideal Use Cases
AReaL excels in scenarios where reasoning quality and training efficiency are both critical:
- Mathematical reasoning agents: Train models on GSM8K or similar datasets using GRPO or PPO with self-correction loops.
- Code generation and debugging: Optimize agents that write, test, and refine programs through iterative feedback.
- Search and browsing agents: Build end-to-end systems like ASearcher, which combines reasoning, web navigation, and summarization.
- Tool-integrated agents: Deploy models that dynamically invoke external APIs or functions during inference.
- Large-scale RL experiments: Scale training from a single node to 1,000+ GPUs with minimal configuration changes.
Note: AReaL is not designed for standard supervised fine-tuning (SFT) or generic text generation. It’s purpose-built for reinforcement learning on reasoning-intensive tasks.
Getting Started: From Laptop to Cluster
AReaL lowers the barrier to entry with ready-to-run examples. To train a math agent on GSM8K using GRPO on a single machine:
python3 -m areal.launcher.local examples/math/gsm8k_rl.py --config examples/math/gsm8k_grpo.yaml
For distributed training across a Ray cluster (e.g., 2 nodes × 8 GPUs):
python3 -m areal.launcher.ray examples/math/gsm8k_rl.py --config examples/math/gsm8k_grpo.yaml cluster.n_nodes=2 cluster.n_gpus_per_node=8
The system automatically downloads the Qwen2-1.5B-Instruct model and GSM8K dataset. For newcomers, the AReaL-lite quickstart guide is the recommended onboarding path.
Limitations and Practical Considerations
While powerful, AReaL isn’t a one-size-fits-all solution:
- RL expertise required: Users should understand core concepts like advantage estimation, reward shaping, and policy gradients. AReaL doesn’t abstract away RL fundamentals.
- Not for SFT-only workflows: If your goal is purely supervised tuning, other frameworks may be more appropriate.
- Model compatibility: Full support depends on your Hugging Face Transformers version and backend choice (e.g., vLLM, SGLang). Custom or non-standard architectures may require additional integration effort.
- Configuration overhead: Although AReaL-lite simplifies prototyping, production deployments across large clusters demand careful tuning of worker ratios and data pipelines to control staleness.
Summary
AReaL solves a critical bottleneck in large-scale RL for reasoning LLMs: the inefficiency of synchronous training. By enabling fully asynchronous data generation and model updates, it unlocks unprecedented training speed while maintaining—or even improving—final agent performance. With strong support for multi-turn agentic workflows, diverse RL algorithms, and scalable infrastructure, AReaL is a compelling choice for teams serious about building next-generation reasoning agents. Whether you’re a researcher prototyping with AReaL-lite or an engineer deploying thousand-GPU training jobs, AReaL offers a robust, open-source path forward.