MiniMax-M1 is a breakthrough in open large language models: it’s the world’s first open-weight, large-scale hybrid-attention reasoning model. Designed for engineers, researchers, and product teams who need AI that can reason deeply over long inputs without breaking the bank, MiniMax-M1 blends cutting-edge architecture with practical efficiency. Built on a hybrid Mixture-of-Experts (MoE) backbone and enhanced with a novel “Lightning Attention” mechanism, it delivers state-of-the-art performance on complex tasks—especially in software engineering, tool-augmented workflows, and ultra-long-context understanding—while using significantly less compute at inference time.
If you’ve ever struggled with models that run out of context, cost too much to serve, or fail at multi-step reasoning, MiniMax-M1 offers a compelling alternative that’s both powerful and transparent.
What Makes MiniMax-M1 Unique?
1M-Token Native Context Window
MiniMax-M1 natively supports a context length of 1 million tokens—eight times longer than DeepSeek-R1. This isn’t just a number; it means you can feed entire technical manuals, legal contracts, or software repositories into the model in a single pass. Unlike models that require complex chunking or retrieval tricks, M1 handles long sequences end-to-end, preserving coherence and cross-document reasoning.
Lightning Attention: 75% Less Inference Compute
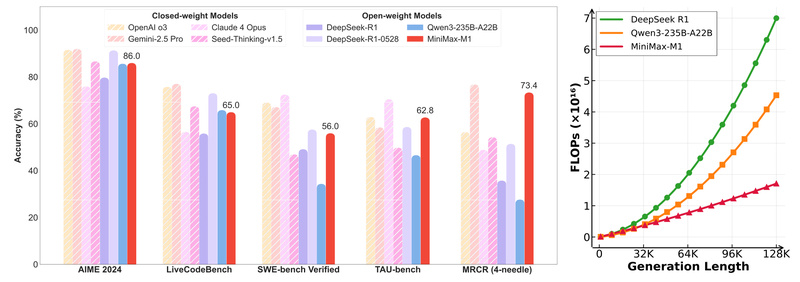
The “Lightning Attention” mechanism is a core innovation that slashes computational costs during generation. For instance, when generating 100K tokens, MiniMax-M1 consumes only 25% of the FLOPs required by DeepSeek-R1. This efficiency makes extended reasoning—from solving math Olympiad problems to debugging legacy codebases—feasible even on constrained infrastructure.
Hybrid MoE Architecture with Massive Scale
MiniMax-M1 scales intelligently: it has 456 billion total parameters but activates only 45.9 billion per token. This hybrid MoE design balances performance and cost, enabling high-capacity reasoning without exploding memory or latency. The result? A model that’s both capable and practical for real-world deployment.
Trained for Real-World Reasoning
Unlike many models trained purely on static datasets, MiniMax-M1 is fine-tuned using large-scale reinforcement learning (RL) on diverse, dynamic environments—including sandboxed software engineering tasks. This RL training, accelerated by a new algorithm called CISPO (which clips importance sampling weights instead of token updates), helps the model develop robust problem-solving strategies rather than just pattern matching.
Where MiniMax-M1 Excels: Practical Use Cases
Software Engineering Agents
On SWE-bench Verified, MiniMax-M1-80K achieves a 56.0% pass rate—outperforming Qwen3-235B (34.4%) and matching DeepSeek-R1-0528 (57.6%). This makes it ideal for building AI coding agents that can localize bugs, propose fixes, and validate patches across large codebases without human intervention.
Long-Context Understanding
In the OpenAI-MRCR benchmark at 128K tokens, MiniMax-M1 scores 73.4%, far ahead of Qwen3-235B (27.7%) and DeepSeek-R1 (35.8%). At the full 1M-token length, it maintains strong performance (56.2%), proving it can truly leverage its massive context window—not just claim it.
Agentic Tool Use
On TAU-bench (airline and retail scenarios), MiniMax-M1 consistently outperforms most open models, with scores up to 67.8% in retail automation. This demonstrates its ability to follow policies, call appropriate tools, and navigate multi-turn interactions—key for enterprise AI assistants.
Complex Reasoning Tasks
From AIME math competitions to MATH-500, MiniMax-M1 matches or exceeds leading models. Its “thinking budget” (40K or 80K steps of internal reasoning) allows it to decompose problems, verify intermediate steps, and arrive at correct answers through structured reasoning—critical for scientific or financial applications.
Getting Started with MiniMax-M1
Recommended Inference Settings
For optimal performance, use:
- Temperature:
1.0 - Top_p:
0.95
These settings encourage diverse, creative, yet coherent outputs—ideal for reasoning-heavy tasks.
System Prompt Templates
Tailor your prompts to the task:
-
General use:
You are a helpful assistant. -
Web development:
You are a web development engineer... Output only the HTML, without any additional descriptive text. Make the UI look modern and beautiful. -
Mathematical reasoning:
Please reason step by step, and put your final answer within boxed{}
Deployment Options
MiniMax-M1 is available as open-weight models on Hugging Face:
MiniMax-M1-40k(intermediate checkpoint)MiniMax-M1-80k(fully trained version)
For production, vLLM is strongly recommended—it provides high throughput, efficient memory management, and batch processing. Transformers-based inference is also supported for experimentation.
Function Calling Support
MiniMax-M1 natively supports structured function calling, enabling integration with external APIs, databases, or custom tools. This is essential for building agentic workflows that interact with real-world systems.
Key Limitations and Practical Considerations
While MiniMax-M1 is powerful, it’s not a plug-and-play solution for every environment:
- Hardware demands: Running the full model locally requires significant GPU memory. Cloud deployment or model quantization may be necessary for smaller teams.
- Prompt sensitivity: Like most reasoning models, performance depends heavily on prompt design. The provided templates are a good starting point, but task-specific tuning may be needed.
- Evaluation dependencies: SWE-bench results rely on the Agentless scaffold with a custom two-stage localization pipeline—not standard retrieval-augmented generation. Reproducing exact scores requires replicating this setup.
That said, the open-weight nature of MiniMax-M1 gives you full control to adapt, audit, and optimize—unlike closed commercial APIs.
How MiniMax-M1 Stacks Up Against Alternatives
Benchmarks tell a clear story: MiniMax-M1 holds its own against both open and commercial leaders:
- Software engineering: Beats Qwen3-235B by over 20 percentage points on SWE-bench Verified.
- Long-context: Leads all open models on OpenAI-MRCR at both 128K and 1M tokens.
- Tool use: Surpasses DeepSeek-R1 and Qwen3 on TAU-bench retail scenarios.
- Math & reasoning: Matches or exceeds DeepSeek-R1 on AIME and ZebraLogic.
While models like Claude 4 Opus or o3 may lead on some metrics, they’re closed and costly. MiniMax-M1 offers comparable reasoning power with full transparency, reproducibility, and control—making it a strategic choice for teams building mission-critical AI systems.
Summary
MiniMax-M1 redefines what’s possible with open large language models. By combining a 1M-token context window, Lightning Attention for efficient inference, and RL-driven reasoning capabilities, it directly addresses real pain points: high serving costs, limited context handling, and weak multi-step problem solving. Whether you’re building an AI coding agent, analyzing massive documents, or deploying a tool-using assistant, MiniMax-M1 provides a scalable, transparent, and high-performing foundation. With open weights, clear deployment guidance, and strong benchmark results, it empowers technical teams to innovate without vendor lock-in—making it a standout choice for the next generation of AI applications.