Retrieval-Augmented Generation (RAG) has become a go-to strategy for grounding large language model (LLM) responses in real-world knowledge. By pulling relevant documents into the generation process, RAG significantly reduces—but doesn’t eliminate—hallucinations. In practice, RAG systems can still produce answers that appear plausible yet contradict or overextend the retrieved evidence.
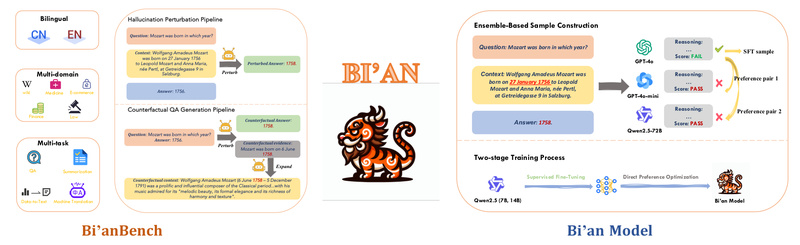
This is where Bi’an steps in. Bi’an is a purpose-built framework that tackles the critical gap in RAG evaluation: reliable, scalable hallucination detection. It introduces two tightly integrated components: (1) Bi’anBench, a rigorously curated bilingual (English–Chinese) benchmark dataset covering diverse RAG failure modes, and (2) a family of lightweight, open-source judge models fine-tuned specifically for hallucination identification. These models deliver performance that rivals or exceeds much larger closed-source LLMs—despite being only 14B parameters or smaller.
For technical decision-makers evaluating or deploying RAG systems—especially in multilingual or high-stakes domains like finance, legal, or healthcare—Bi’an offers a practical, open, and efficient solution to validate factual consistency without relying on opaque or costly APIs.
Why Hallucination Detection in RAG Remains a Challenge
While RAG improves answer grounding, its output quality still hinges on retrieval relevance, context integration, and the LLM’s internal reasoning. Common failure patterns include:
- Unsupported claims: The model asserts facts not present in retrieved documents.
- Contradictions: The response directly conflicts with the evidence.
- Overgeneralization: The model extrapolates beyond what the source material justifies.
Traditional evaluation often leans on “LLM-as-a-Judge” approaches, which are easy to deploy but suffer from two major limitations:
- Lack of standardized, scenario-rich benchmarks to test across varied RAG configurations.
- Absence of specialized, domain-optimized judge models—generic LLMs aren’t trained to detect subtle factual inconsistencies with high precision.
Bi’an directly addresses both issues.
Core Components of Bi’an
A Bilingual Benchmark for Realistic RAG Evaluation
Bi’anBench is not just another QA dataset. It’s designed to mirror real-world RAG challenges:
- Covers multiple RAG scenarios, including single-hop and multi-hop reasoning.
- Includes annotations for hallucination types (e.g., contradiction, unsupported inference).
- Supports both English and Chinese, enabling cross-lingual robustness testing.
This benchmark allows developers to rigorously evaluate not just whether an answer is “correct,” but whether it is faithful to the retrieved context—a crucial distinction in professional applications.
Lightweight, High-Performance Judge Models
Bi’an’s judge models are fine-tuned from compact open-source LLMs (e.g., 7B–14B scale). Despite their modest size, they outperform baseline models with 5× larger parameter counts and match the accuracy of leading closed-source judges on Bi’anBench.
Key advantages:
- Efficiency: Run inference locally or on modest cloud instances.
- Transparency: Fully open weights and evaluation protocols (upcoming release).
- Specialization: Trained explicitly on hallucination detection signals, not general QA.
This makes Bi’an ideal for teams that need consistent, auditable, and cost-effective evaluation at scale.
Where Bi’an Delivers the Most Value
Bi’an shines in scenarios where factuality, auditability, and multilingual support are non-negotiable:
- Enterprise RAG deployments: Validate that customer-facing chatbots or internal assistants don’t invent policies, regulations, or technical specs.
- Regulated domains: In legal, healthcare, or financial services, even minor hallucinations can have serious consequences—Bi’an provides a measurable safety net.
- Multilingual knowledge systems: Test consistency across language boundaries when retrieving and generating in both English and Chinese.
- RAG research & development: Use Bi’anBench as a standardized testbed to compare retrieval strategies, rerankers, or generation prompts objectively.
Because Bi’an is part of the broader KAG (Knowledge Augmented Generation) ecosystem from OpenSPG, it integrates naturally with structured knowledge graphs, hybrid reasoning engines, and schema-constrained knowledge construction—making it especially powerful for professional knowledge bases.
Getting Started with Bi’an
Bi’an is developed under the OpenSPG/KAG project and will be released via the official GitHub repository: https://github.com/OpenSPG/KAG.
While the full dataset and models are marked as “coming soon” in the paper, the KAG framework already provides:
- Infrastructure for building private and public knowledge bases.
- Logical reasoning and multi-hop QA capabilities.
- Support for streaming inference, reference tracing, and graph-based retrieval.
Once released, Bi’an’s judge models and benchmark will be accessible through the same repository, allowing developers to:
- Evaluate existing RAG pipelines against Bi’anBench.
- Integrate Bi’an judges as automatic verifiers in production workflows.
- Fine-tune or extend the models for domain-specific hallucination patterns.
Users familiar with Docker and Python can already explore KAG’s architecture and prepare their environments using the provided quick-start guides.
Limitations and Practical Considerations
Bi’an is a focused tool—not a general-purpose evaluator. Keep in mind:
- It is specialized for hallucination detection in RAG outputs, not for assessing coherence, style, or task completion.
- The benchmark and models are not yet publicly available as of the paper’s writing (but are expected soon).
- Effective use assumes basic familiarity with RAG architectures and evaluation workflows (e.g., how to extract retrieved context and model responses for judging).
Additionally, while Bi’an supports bilingual evaluation, its current scope is limited to English and Chinese. Extensions to other languages would require additional data and tuning.
Summary
Bi’an solves two real, persistent problems in the RAG ecosystem: the absence of comprehensive hallucination benchmarks and the lack of efficient, specialized judge models. By delivering a bilingual evaluation suite and lightweight yet high-performing detectors, it empowers technical teams to build more trustworthy, auditable, and factually grounded AI systems—without relying on black-box commercial APIs.
For project leads, researchers, and engineers working on knowledge-intensive LLM applications, Bi’an represents a significant step toward reliable, open, and scalable hallucination control. Keep an eye on the OpenSPG/KAG repository for its official release—and prepare to integrate a new standard for RAG quality assurance into your pipeline.