Evaluating large language models (LLMs) has become increasingly challenging. Traditional benchmarks—like MMLU, GSM8K, or Big-Bench Hard—are static, fixed in complexity, and often contaminated by training data inadvertently absorbed during model pretraining. This leads to inflated performance scores that don’t reflect a model’s true reasoning ability. Enter DyVal (Dynamic Evaluation of Large Language Models), a novel evaluation protocol integrated into Microsoft’s PromptBench library. DyVal addresses these limitations by generating fresh, on-the-fly evaluation samples with controllable difficulty, specifically tailored for reasoning-intensive tasks such as mathematics, logical inference, and algorithmic problem-solving.
Unlike conventional benchmarks that offer a one-time snapshot, DyVal enables adaptive, future-proof assessment—ensuring evaluations evolve alongside model capabilities. For technical decision-makers—whether you’re selecting models for a coding assistant, validating research claims, or fine-tuning custom LLMs—DyVal provides a more rigorous, reliable, and contamination-resistant testing ground.
Why DyVal Matters: Solving Key Evaluation Pitfalls
Static benchmarks suffer from three critical flaws:
- Data Contamination: Many LLMs are trained on vast, uncurated corpora that may include benchmark questions, leading to memorization rather than genuine reasoning.
- Fixed Difficulty: Benchmarks rarely scale in complexity, failing to stress-test models beyond baseline performance.
- Limited Generalization Signal: A single score on a static set reveals little about how a model handles novel, structurally complex problems.
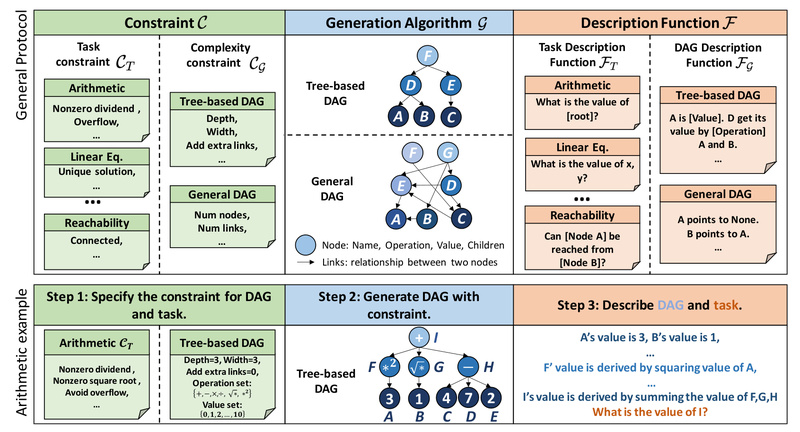
DyVal directly tackles these issues. By dynamically generating evaluation instances at test time, it ensures zero overlap with training data. Moreover, its design leverages directed acyclic graphs (DAGs) to construct reasoning problems with layered dependencies—mimicking real-world complexity where solving one subproblem informs the next. This graph-informed approach allows precise control over task difficulty, enabling nuanced performance profiling across complexity levels.
Core Features That Make DyVal Stand Out
DyVal isn’t just another benchmark—it’s a flexible evaluation framework with several distinctive capabilities:
1. Graph-Informed Problem Generation
DyVal encodes reasoning tasks as DAGs, where nodes represent subproblems and edges define logical dependencies. This structure ensures generated problems are coherent, non-redundant, and scalable in depth—ideal for testing multi-step reasoning.
2. On-the-Fly Sample Synthesis
Evaluation samples are generated during runtime, not pre-collected. This eliminates contamination risks and ensures every evaluation instance is truly “unseen” by the model.
3. Controllable Complexity
Users can specify parameters to adjust problem depth, branching factor, or logical operations, enabling targeted stress tests (e.g., “generate 100 math problems that require exactly three inference steps”).
4. Dual Purpose: Evaluation + Training Data
Experiments in the DyVal paper show that its generated samples aren’t just useful for evaluation—they also serve as high-quality fine-tuning data that improves model performance on standard benchmarks like MMLU and GSM8K.
5. Seamless Integration via PromptBench
DyVal is natively supported in PromptBench, a mature, open-source LLM evaluation library. This means you can plug DyVal into existing evaluation pipelines with minimal code changes.
Ideal Use Cases for Technical Decision-Makers
DyVal shines in scenarios where reasoning reliability is non-negotiable:
- Pre-deployment model validation: Before launching an AI-powered analytics or coding assistant, use DyVal to stress-test reasoning robustness beyond standard benchmarks.
- Model selection and comparison: Compare LLMs (e.g., GPT-4 vs. Llama 3 vs. Claude) on dynamically generated, equally difficult problems—ensuring apples-to-apples comparisons without contamination bias.
- Fine-tuning data curation: Harvest DyVal-generated samples to augment your training set, especially for domains requiring structured reasoning (e.g., legal analysis, scientific Q&A, or algorithm synthesis).
- Research reproducibility: In academic or industrial research, use DyVal to demonstrate that performance gains stem from improved reasoning—not memorization of static test sets.
Getting Started with DyVal
Using DyVal is straightforward thanks to its integration into PromptBench:
- Install PromptBench via pip or GitHub:
pip install promptbench # or for latest features: git clone https://github.com/microsoft/promptbench.git cd promptbench && pip install -r requirements.txt
- Import and initialize DyVal:
import promptbench as pb
dyval_dataset = pb.Dataset("DyVal", task="math", complexity=3)
- Run evaluation using the provided pipeline (see
examples/dyval.ipynbin the repository). The API handles sample generation, prompting, and scoring automatically.
No need to build problem generators from scratch—DyVal’s ready-to-use modules cover math, logic, and algorithmic reasoning out of the box.
Limitations and Practical Considerations
While powerful, DyVal has boundaries to keep in mind:
- Task scope: DyVal is specialized for reasoning tasks. It doesn’t evaluate general language fluency, summarization, or stylistic generation.
- Dependency on PromptBench: You must use the PromptBench ecosystem, which requires basic Python and LLM evaluation familiarity.
- Complementary, not replacement: DyVal enhances—but doesn’t replace—traditional benchmarks. Use it alongside static evaluations for a complete picture.
- Resource overhead: Dynamic generation requires more compute than loading pre-built datasets, though the trade-off in evaluation integrity is often worth it.
Summary
DyVal redefines how we evaluate LLM reasoning by replacing static, contamination-prone benchmarks with dynamic, graph-structured, and complexity-controlled evaluation. Integrated into Microsoft’s PromptBench, it offers technical teams a practical, scalable way to assess—and even improve—LLM performance in reasoning-heavy applications. If your work depends on trustworthy model evaluation beyond surface-level accuracy, DyVal is a critical tool to adopt.