In modern computer vision, practitioners often juggle multiple foundation models—CLIP for vision-language alignment, DINOv2 for dense feature extraction, and SAM for zero-shot segmentation—each excelling in its niche but rarely working together seamlessly. This fragmentation forces engineers to maintain separate inference pipelines, manage complex model orchestration, and accept suboptimal performance when tasks require cross-domain understanding.
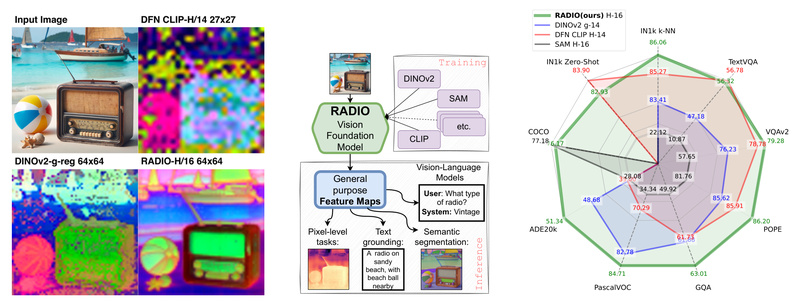
Enter AM-RADIO (Agglomerative Model – Reduce All Domains Into One): a unified vision foundation model that distills the capabilities of multiple state-of-the-art teachers—including CLIP variants, DINOv2, and SAM—into a single, highly capable backbone. Developed by NVIDIA Research and accepted at CVPR 2024 and CVPR 2025, AM-RADIO doesn’t just merge models—it enhances them. By leveraging multi-teacher distillation with innovations like PHI-S (label-free distribution balancing) and FeatSharp (feature sharpening), AM-RADIO delivers stronger performance across a wide range of tasks while supporting flexible input resolutions and commercial deployment.
For technical decision-makers evaluating vision backbones for multimodal AI, robotics, or enterprise vision systems, AM-RADIO offers a compelling "one model to rule them all" solution—without sacrificing specialization.
Core Capabilities: One Model, Multiple Superpowers
AM-RADIO’s design philosophy centers on integration without compromise. Unlike traditional ensembles or cascaded pipelines, it encodes the distinctive strengths of its teacher models directly into its architecture through distillation. This results in a single model that simultaneously supports:
- Zero-shot vision-language understanding (inherited from CLIP and SigLIP teachers)
- Pixel-level dense prediction, including open-vocabulary semantic segmentation (via SAM and DINOv2 knowledge)
- High-resolution, non-square image support (from 192px up to 2048px, depending on the variant)
- Strong transfer performance across classification, object detection, segmentation, and vision-language tasks
Crucially, these capabilities are available out of the box, without task-specific fine-tuning. This makes AM-RADIO uniquely suited for applications where rapid prototyping, deployment efficiency, or cross-task consistency matters—such as building multimodal agents or unified perception stacks in robotics.
Performance Beyond the Teachers
Benchmarking shows AM-RADIO doesn’t just match its teachers—it consistently exceeds them:
- +6.8% improvement in ImageNet zero-shot classification over the best individual teacher
- +2.39% gain in kNN accuracy
- +3.8% higher mIoU on ADE20k semantic segmentation under linear probing
- 1.5% average gain in LLaVa-1.5 vision-language benchmarks (GQA, POPE, TextVQA, VQAv2)
Even more impressively, the E-RADIO variant achieves 6–10× faster inference than CLIP or DINOv2 while maintaining competitive accuracy—making it ideal for latency-sensitive applications. Meanwhile, the C-RADIO series (e.g., C-RADIOv3-B/L/H/g) is released under NVIDIA’s Open Model License, enabling commercial use in products—a rare advantage among high-performance foundation models.
Recent C-RADIOv3 models, trained with FeatSharp and broader teacher sets (including Florence2 and SigLIP2-NaFlex), now achieve 83.54% zero-shot top-1 accuracy on ImageNet and 52.75 mIoU on ADE20k, rivaling models with far larger parameter counts.
Ideal Use Cases for Practitioners
AM-RADIO shines in scenarios where diverse visual understanding is needed within a single, efficient pipeline:
- Multimodal AI assistants: Replace CLIP in LLaVa-style architectures to improve both spatial grounding and semantic reasoning.
- Unified perception in robotics/AR/VR: Use one model for scene classification, object detection, and segmentation—reducing system complexity.
- Enterprise vision platforms: Standardize on one backbone for internal tools handling document analysis, industrial inspection, and retail analytics.
- Research prototyping: Rapidly iterate on novel tasks without switching between incompatible model APIs or feature spaces.
Because AM-RADIO provides both a global summary token (for classification or language alignment) and rich spatial features (for dense prediction), it naturally bridges tasks that typically require separate models.
Getting Started: Simple Integration via TorchHub or Hugging Face
Loading and running AM-RADIO is straightforward. Here’s how to use the latest C-RADIOv3-H model via TorchHub:
import torch
from PIL import Image
from torchvision.transforms.functional import pil_to_tensor
model = torch.hub.load('NVlabs/RADIO', 'radio_model', version='c-radio_v3-h')
model.cuda().eval()
# Load and preprocess image (values in [0, 1])
img = Image.open('example.jpg').convert('RGB')
x = pil_to_tensor(img).float().div(255).unsqueeze(0).cuda()
# Adjust to nearest supported resolution
nearest_res = model.get_nearest_supported_resolution(*x.shape[-2:])
x = torch.nn.functional.interpolate(x, nearest_res, mode='bilinear')
# Run inference
summary, spatial_features = model(x, feature_fmt='NCHW') # spatial_features in (B, C, H, W)
For Hugging Face users:
from transformers import AutoModel, CLIPImageProcessor
model = AutoModel.from_pretrained("nvidia/C-RADIO", trust_remote_code=True).cuda()
processor = CLIPImageProcessor.from_pretrained("nvidia/C-RADIO")
inputs = processor(images=image, return_tensors="pt").pixel_values.cuda()
summary, features = model(inputs)
Advanced users can also activate adaptors (e.g., clip, sam, dino_v2) to emulate teacher-specific outputs—enabling zero-shot classification with CLIP’s language space or SAM-style segmentation masks, all from the same forward pass.
Limitations and Practical Considerations
While powerful, AM-RADIO has important constraints:
- Licensing: Only C-RADIO models (prefixed with “c-“) are commercially licensed. RADIO and E-RADIO fall under NVIDIA’s non-commercial license (NSCL).
- E-RADIO optimization: Its speed advantage requires calling
model.model.set_optimal_window_size((H, W))for each input resolution to avoid performance drops. - Memory usage: High-resolution inference (e.g., 2048px with ViT-g) demands substantial GPU memory—plan accordingly.
- Domain specialization: While AM-RADIO generalizes well, extreme domains (e.g., medical imaging, satellite analytics) may still benefit from fine-tuning.
Summary
AM-RADIO redefines what a vision foundation model can be: not just a specialist, but a generalist synthesizer that unifies language grounding, segmentation, and detection into one efficient, high-performing architecture. With commercial variants (C-RADIO), speed-optimized versions (E-RADIO), and seamless integration via standard libraries, it offers technical leaders a rare opportunity to simplify their vision stack while improving performance across the board. If your project demands versatility, efficiency, and state-of-the-art results without model sprawl, AM-RADIO is a compelling choice worth evaluating today.