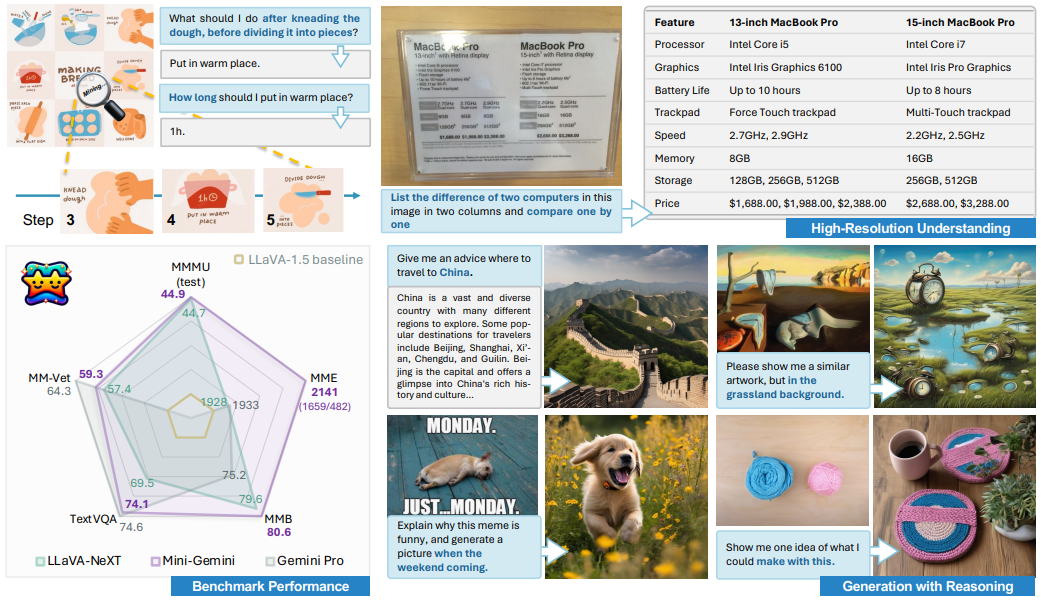
In today’s AI landscape, multimodal systems that understand both images and language are no longer a luxury—they’re a necessity. Yet, many teams struggle to access Vision-Language Models (VLMs) that rival the capabilities of closed, proprietary systems like GPT-4V or Google’s Gemini without massive infrastructure or API dependencies. Enter Mini-Gemini, an open-source framework built on LLaVA that dramatically enhances VLM performance through three key innovations: dual-resolution visual encoding, high-quality multimodal instruction data, and integrated reasoning-generation capabilities.
Unlike typical research-only models, Mini-Gemini delivers state-of-the-art zero-shot results across benchmarks like TextVQA, MMMU, and MathVista—even outperforming some private models—while remaining fully open, customizable, and deployable on your own hardware. Whether you’re building an educational assistant, a document-processing pipeline, or an accessibility tool, Mini-Gemini gives you enterprise-grade multimodal intelligence without vendor lock-in.
What Makes Mini-Gemini Different?
Mini-Gemini isn’t just another fine-tuned VLM. It systematically addresses three core limitations of current open-source vision-language systems:
1. High-Resolution Visual Understanding Without Token Explosion
Most VLMs downscale images to fit fixed-resolution inputs (e.g., 336×336), losing critical details in charts, text, or complex scenes. Mini-Gemini introduces a dual visual encoder architecture:
- A low-resolution (LR) encoder (CLIP-ViT-L at 336px) provides global context.
- A high-resolution (HR) encoder (ConvNeXt at 768px or 1536px) refines local patches without increasing total token count.
This “patch info mining” mechanism aligns HR details with LR queries, enabling precise understanding of fine-grained visuals—like table entries or diagram annotations—while keeping inference efficient.
2. Curated, High-Quality Multimodal Training Data
Mini-Gemini leverages MGM-Instruct, a meticulously constructed dataset blending:
- Instruction-following examples from ShareGPT4V and ALLaVA-4V
- Reasoning-heavy tasks from GQA, ChartQA, DocVQA, and AI2D
- Visual grounding from COCO and VisualGenome
This data mix trains models not just to describe images, but to reason about relationships, extract structured information, and generate accurate explanations—critical for real-world applications.
3. Unified Comprehension and Generation
Where many VLMs focus only on question answering, Mini-Gemini supports end-to-end multimodal workflows: understand an image, reason step-by-step, and generate text or new visual content (via optional Diffusion integration). This “any-to-any” capability enables richer interactions, such as:
“Explain this financial chart, then generate a simplified version for a beginner audience.”
When Should You Use Mini-Gemini?
Mini-Gemini excels in scenarios demanding detailed visual analysis paired with fluent, logical language output:
- Document Intelligence: Extract and interpret text, tables, and forms from invoices, contracts, or scanned reports—even handwriting with optional OCR.
- Educational Tools: Tutor students by explaining diagrams, solving math problems with visual steps, or generating study aids from textbook figures.
- Accessibility Assistants: Describe complex scenes, product labels, or transit maps for visually impaired users with contextual reasoning.
- Multimodal Chatbots: Power customer support agents that “see” user-uploaded images (e.g., error screenshots, product photos) and respond with actionable guidance.
If your use case involves interpreting structured visuals (charts, graphs, layouts) or requires explanatory reasoning beyond captioning, Mini-Gemini is purpose-built for you.
Getting Started: Practical Adoption Paths
Mini-Gemini lowers the barrier to high-performance VLM deployment through flexible, developer-friendly interfaces:
Pre-Trained Models for Immediate Use
Choose from 11+ variants (2B to 34B parameters) with or without HD support, based on LLaMA-3, Mixtral, Gemma, or Yi. Models are available on Hugging Face and GitHub, with full weights for research use.
Lightweight Inference Options
Run inference with minimal setup:
- CLI mode: Process images via command line with optional OCR (
--ocr) or image generation (--gen). - Quantization: Use 4-bit or 8-bit models (
--load-4bit) to fit larger models (e.g., 13B-HD) on a single 24GB GPU. - Multi-GPU support: Distribute workloads across GPUs for HD models (672×1536 resolution).
Local Demo for Rapid Prototyping
Launch a Gradio web UI in minutes to test models interactively. Compare multiple checkpoints side-by-side by spinning up separate “model workers”—ideal for evaluating trade-offs between speed (2B) and reasoning depth (34B-HD).
All code and scripts are organized for easy customization, and Mini-Gemini inherits LLaVA’s modular design, making integration into existing pipelines straightforward.
Limitations and Strategic Considerations
While Mini-Gemini sets a new standard for open VLMs, be mindful of these constraints:
- License Restrictions: Models and data are released under CC BY-NC 4.0, restricting use to non-commercial research. Commercial deployment requires separate licensing.
- Hardware Demands: HD modes (e.g., 13B-HD at 672×1536) benefit from A100 80GB GPUs. Quantization helps but may slightly reduce accuracy.
- Training Overhead: Reproducing results requires access to large datasets (1.8M+ instruction samples) and multi-node A100 clusters—though inference is far more accessible.
- Domain Specialization: While strong in general benchmarks, niche domains (e.g., medical imaging) may still require task-specific fine-tuning.
Summary
Mini-Gemini represents a strategic leap for teams seeking Gemini- or GPT-4V-level multimodal performance without closed ecosystems. By combining dual-resolution vision, reasoning-rich data, and unified generation, it delivers exceptional zero-shot accuracy across real-world tasks—from document parsing to educational tutoring—while remaining fully open and adaptable. For technical leaders evaluating vision-language solutions, Mini-Gemini offers a rare combination: cutting-edge results, transparent architecture, and deployment flexibility—all without API dependencies or black-box constraints. If your project demands deep visual understanding paired with articulate, logical responses, Mini-Gemini is the open-source answer you’ve been waiting for.