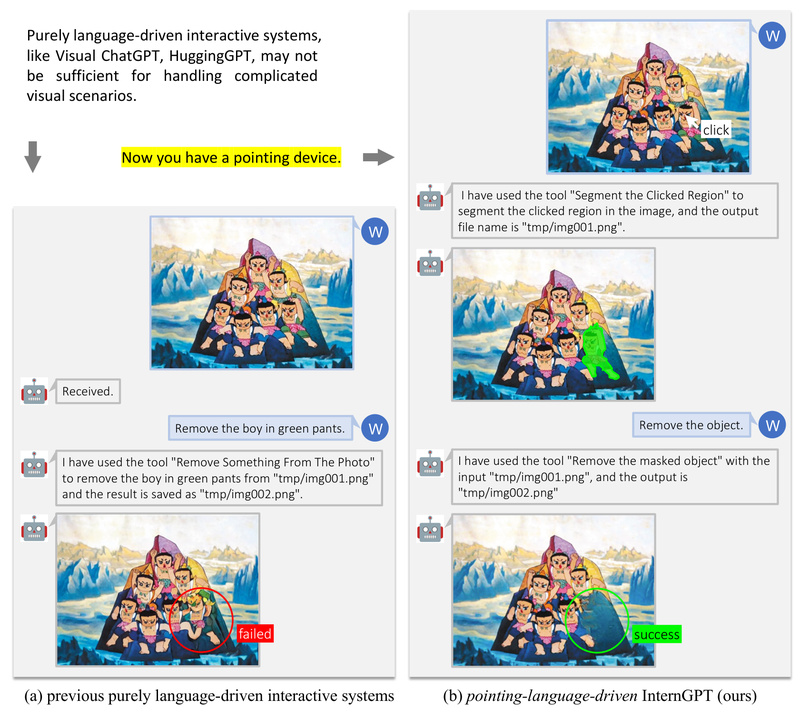
In today’s AI landscape, large language models (LLMs) like ChatGPT have transformed how we interact with software—through natural language. But when it comes to visual tasks—editing images, analyzing complex scenes, or generating content from sketches—pure language often falls short. How do you precisely refer to “that blue car on the left behind the lamppost” in words? The answer is: you don’t. You point.
Enter InternGPT (also known as iGPT): a multimodal interactive system that fuses the reasoning power of LLMs with intuitive non-verbal inputs like clicks, drags, and scribbles. Instead of relying solely on ambiguous text prompts, InternGPT lets users directly interact with visual content on screen—click to select, drag to move, draw to generate—while leveraging a powerful vision-language model to interpret and act on those interactions. This approach dramatically improves accuracy and efficiency, especially in complex visual scenarios with multiple objects.
Beyond Text: Why Non-Verbal Interaction Matters
Traditional vision-language systems force users to describe everything in words. This works poorly when precision is needed: “remove the second person from the left” is error-prone; clicking on the person is not. InternGPT introduces pointing as a core input modality, enabling users to ground their requests in visual space.
This design—captured in its name (Interaction, Nonverbal, ChatGPT)—solves a real-world pain point for designers, content creators, and AI researchers: the mismatch between high-level language and low-level visual control. By combining gesture-based input with LLM reasoning, InternGPT bridges the gap between human intent and machine execution.
Core Capabilities That Deliver Real-World Value
InternGPT isn’t just a demo—it’s a modular toolkit for vision-centric workflows, powered by a suite of integrated models and tools:
Interactive Image Editing with Precision
Users can click on any region of an image to:
- Segment it (using Segment Anything),
- Extract text via OCR,
- Remove the selected area (via inpainting),
- Or replace it with a new concept (e.g., “replace the masked region with a vintage bicycle”).
This level of control is impossible with text-only prompts and is invaluable for rapid prototyping or content moderation.
Generative Workflows from Multiple Modalities
InternGPT supports diverse input combinations:
- Scribble-to-image: Draw on a whiteboard and generate a photorealistic image based on your sketch and a text prompt.
- Audio-to-image: Upload a sound clip (e.g., birds chirping) and generate a matching scene using ImageBind’s cross-modal alignment.
- Image + text + audio: Fuse multiple signals to guide generation with unprecedented context.
DragGAN Integration for Intuitive Manipulation
With built-in DragGAN support, users can click to define handle points (blue = start, red = target) and drag objects within an image—changing pose, position, or perspective in real time. This is particularly useful for fashion, product design, and visual effects prototyping.
High-Quality Multimodal Dialogue via Husky
At the heart of InternGPT is Husky, a fine-tuned vision-language model that achieves 93.89% of GPT-4’s quality on visual Q&A tasks while running more efficiently than calling external APIs. This enables responsive, accurate answers to questions like “What’s written on that sign?” or “How many animals are in this photo?”
Comprehensive Video Understanding
Beyond static images, InternGPT supports:
- Action recognition,
- Video captioning,
- Dense captioning (describing multiple events per frame),
- And highlight interpretation—making it suitable for sports analysis, surveillance, or educational content indexing.
Getting Started: Flexible Deployment for Real Teams
InternGPT offers two paths for adoption:
-
Online Demo: Try it instantly at igpt.opengvlab.com (note: queues may occur during peak usage).
-
Local Deployment: For full control and privacy, clone the repository and run it on your own GPU. The system supports selective module loading—for example, run only DragGAN with:
python -u app.py --load "StyleGAN_cuda:0" --tab "DragGAN" --port 3456 --https -e
The
-eflag significantly reduces memory usage, making it feasible even on modest hardware.
This modularity means teams can integrate only the features they need—avoiding bloat and dependency overhead.
Ideal Use Cases for Product and Research Teams
InternGPT shines in scenarios where visual precision and interactive control are non-negotiable:
- Design & Creative Tools: Enable non-technical users to edit images via natural gestures instead of complex UIs.
- AI-Powered Customer Support: Let users circle problematic areas in a photo (“Why is this part blurry?”) and get instant analysis.
- Research Prototyping: Test multimodal interaction hypotheses without building a full stack from scratch.
- Content Moderation: Quickly mask or replace sensitive visual elements using direct selection.
- Education & Accessibility: Combine OCR, segmentation, and speech to assist visually impaired users in understanding images.
Critically, InternGPT excels where pure language fails: scenes with three or more objects, overlapping elements, or ambiguous references—common in real-world imagery.
Current Limitations and Practical Notes
While powerful, InternGPT is still under active development. Users should be aware of:
- The online demo may experience delays or temporary outages.
- Full functionality requires a GPU for local deployment; CPU-only mode is not supported.
- Advanced features (e.g., video dense captioning) demand significant VRAM—use selective loading to manage resources.
- Language support is currently English-only; Chinese and other languages are planned.
- Some integrations (e.g., VisionLLM, MOSS) remain on the roadmap.
That said, the project is open-source (Apache 2.0), well-documented, and actively maintained—making it a safe bet for forward-looking teams.
Summary
InternGPT redefines what’s possible in human-AI visual collaboration. By moving beyond text-only interaction and embracing direct manipulation—clicks, drags, scribbles—it solves real precision and ambiguity problems that plague conventional vision-language systems. With modular tools, strong performance (via Husky), and support for cutting-edge techniques like DragGAN and ImageBind, it offers a practical, extensible platform for teams building the next generation of multimodal applications. For project leads evaluating AI solutions for visual tasks, InternGPT isn’t just innovative—it’s immediately actionable.