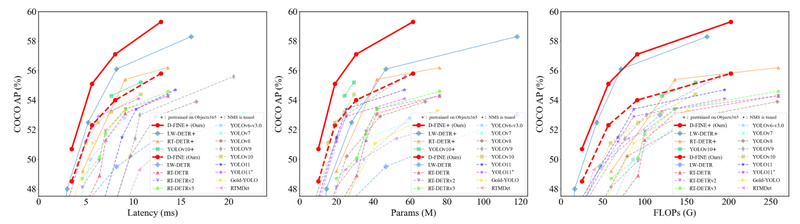
Object detection has long faced a fundamental trade-off: high accuracy or real-time speed—but rarely both. Enter D-FINE, a breakthrough real-time object detector that redefines how DETR-based models handle bounding box regression. By introducing a novel approach called Fine-grained Distribution Refinement (FDR) and a knowledge distillation strategy named Global Optimal Localization Self-Distillation (GO-LSD), D-FINE delivers state-of-the-art accuracy—up to 59.3% AP on COCO when pretrained on Objects365—while maintaining blazing-fast inference speeds of up to 472 FPS on an NVIDIA T4 GPU.
What truly sets D-FINE apart is that it achieves these gains without adding any computational cost during inference. This means you get higher precision, especially on challenging cases like small, blurred, or occluded objects, without sacrificing latency—making it ideal for deployment in resource-constrained, real-world applications.
Why D-FINE Solves Real Engineering Challenges
Redefining Regression as Distribution Refinement
Traditional DETR models predict fixed bounding box coordinates directly, which limits their ability to express uncertainty or fine-grained positional information. D-FINE replaces this with iterative refinement of probability distributions over possible box locations. This fine-grained representation allows the model to better capture subtle spatial cues, dramatically improving localization accuracy—especially critical for small or partially visible objects.
Stable Training with Self-Distillation
Training deep detection models can be unstable and data-hungry. D-FINE’s GO-LSD mechanism addresses this by distilling localization knowledge from the final (most refined) decoder layer back to earlier layers. This bidirectional optimization not only stabilizes training but also simplifies the residual learning task for deeper layers, leading to faster convergence and higher final accuracy—all with negligible extra parameters or training overhead.
Plug-and-Play Compatibility with Existing DETRs
D-FINE isn’t just a standalone model—it’s a drop-in enhancement for a wide range of DETR architectures. Experiments show it can boost AP by up to 5.3% when integrated into other DETR variants, making it a powerful tool for teams already invested in transformer-based detection pipelines.
Ideal Use Cases: Where D-FINE Excels
D-FINE shines in dynamic, real-world environments where both speed and precision are non-negotiable:
- Autonomous vehicles navigating dense urban traffic with motion blur and occlusion
- Surveillance systems detecting small objects (e.g., backpacks, traffic lights) under backlighting or low-light conditions
- Drone and robotics vision requiring real-time response with accurate bounding boxes
- Video analytics platforms processing high-frame-rate streams without compromising detection quality
Its strong generalization—especially when pretrained on the Objects365 dataset (which contains 365 diverse object categories)—makes it particularly effective in complex scenes with varied object types. However, users should note that for extremely simple or narrow-domain tasks (e.g., detecting only one or two object classes), Objects365 pretraining might lead to overfitting, and fine-tuning from COCO-only weights could be preferable.
Getting Started: Easy Adoption for Practitioners
D-FINE is designed for rapid integration and deployment:
Flexible Model Sizes
Choose from five variants—D-FINE-N, S, M, L, X—ranging from 4M to 62M parameters, allowing you to balance accuracy and speed based on your hardware constraints. The smallest variant (D-FINE-N) achieves 42.8% AP at 472 FPS, while the largest (D-FINE-X) delivers 55.8% AP at 78 FPS—all on a single T4 GPU.
Support for Custom Datasets
Training on your own data is straightforward. Just format your annotations in COCO JSON style, update the config file, and disable category remapping (remap_mscoco_category: False). The codebase includes ready-to-use YAML templates for custom training, tuning, and evaluation.
Seamless Deployment
D-FINE supports export to ONNX and TensorRT, enabling optimized inference in production. Tools are provided for benchmarking latency, visualizing detections (via FiftyOne or direct image/video inference), and converting model weights.
Best Practice: Leverage Pretrained Weights
For most real-world applications, start with Objects365-pretrained models and fine-tune on your target dataset. This leverages broad visual knowledge and often yields significantly better performance than training from scratch—especially on complex scenes.
Limitations and Practical Considerations
While D-FINE offers an exceptional speed-accuracy balance, keep these points in mind:
- Hardware requirements: Training the larger models (L/X) benefits from multi-GPU setups (e.g., 4×T4) for optimal throughput, though inference remains efficient on a single GPU.
- Overfitting risk: Objects365 pretraining may not always help if your task involves very few or highly specialized object categories. Validate performance with and without pretrained weights.
- Input resolution flexibility: You can train at custom resolutions (e.g., 320×320), but ensure consistency across data preprocessing and evaluation settings.
Summary
D-FINE redefines what’s possible in real-time object detection by merging the high accuracy of DETR-style models with the speed demanded by real-world applications. Through its innovative distribution-based regression and self-distillation training, it solves long-standing pain points around localization precision and training stability—without inflating inference cost. Whether you’re building autonomous systems, video analytics tools, or robotics perception stacks, D-FINE offers a compelling combination of performance, efficiency, and ease of adoption.