Monocular metric depth estimation (MMDE)—the task of predicting real-world depth values from a single RGB image—is foundational for 3D perception in robotics, autonomous driving, augmented reality, and more. Yet most existing MMDE models suffer from a critical flaw: they perform well only within the domains they were trained on. Show them an indoor office scene after training on urban street views, or a fisheye image from a consumer drone, and their depth predictions often collapse. This lack of generalization severely limits real-world applicability.
UniDepthV2 directly addresses this problem. Introduced in the paper “UniDepthV2: Universal Monocular Metric Depth Estimation Made Simpler,” it delivers accurate, metrically scaled depth from a single image—without requiring camera intrinsics at inference time—and generalizes robustly across diverse, unseen domains in a zero-shot setting. Trained once, it works everywhere: from NYUv2 indoor scenes to KITTI driving footage, Diode internet photos, and NuScenes multi-camera rigs—consistently outperforming prior methods without any fine-tuning.
For project and technical decision-makers, this means one model can serve multiple deployment environments, drastically reducing the need for dataset-specific retraining or calibration. UniDepthV2 isn’t just another depth estimator—it’s a universal solution engineered for the messy reality of cross-domain applications.
Why Generalization Matters—and How UniDepthV2 Solves It
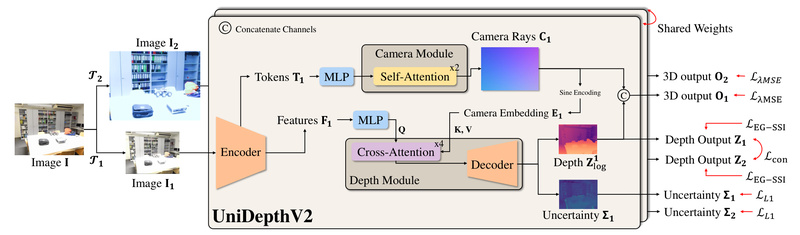
Most MMDE models assume access to known camera parameters or are trained on narrow datasets (e.g., only driving scenes). When deployed outside those conditions, performance degrades rapidly. UniDepthV2 breaks this pattern by decoupling camera modeling from depth prediction through a clever architectural choice: a self-promptable camera module that predicts a dense camera representation directly from the input image. This representation conditions the depth decoder, enabling it to infer metric scale even when no intrinsics are provided.
Further, UniDepthV2 uses a pseudo-spherical output representation, which disentangles geometric priors from depth features. Combined with a geometric invariance loss, this design ensures that depth features remain consistent under camera variations—enhancing robustness across domains.
The result? In zero-shot evaluations across ten benchmarks—including indoor (NYUv2, SUN-RGBD), outdoor (KITTI, DDAD), internet-scraped (Diode), and synthetic (ETH3D)—UniDepthV2 achieves state-of-the-art results. For example, it scores 96.4 on SUN-RGBD (d1 metric) and 87.0 on NuScenes, significantly ahead of Metric3Dv2 and ZoeDepth, especially on cross-domain cases where others falter.
Developer-Friendly Features for Rapid Integration
Beyond generalization, UniDepthV2 is built with deployment in mind:
- No intrinsics required: Predicts metric depth from RGB alone—but optionally accepts ground-truth or custom camera models (including fisheye via
Fisheye624class). - Uncertainty output: Provides per-pixel confidence maps, enabling downstream systems to weigh depth reliability (e.g., in SLAM or obstacle avoidance).
- Flexible input resolution: Handles arbitrary image aspect ratios through internal resolution-level handling, unlike fixed-input models.
- Faster and leaner: Features a simplified architecture compared to UniDepthV1, with faster inference and ONNX support for edge deployment.
- Easy model access: Pre-trained weights are available on Hugging Face and via TorchHub, with just one line of code needed to load.
For example, running inference takes only a few lines:
from unidepth.models import UniDepthV2
model = UniDepthV2.from_pretrained("lpiccinelli/unidepth-v2-vitl14")
predictions = model.infer(rgb_tensor) # returns depth, 3D points, intrinsics, uncertainty
This ease of use lowers the barrier for prototyping and integration into robotics stacks, AR pipelines, or 3D reconstruction workflows.
Where UniDepthV2 Delivers the Most Value
UniDepthV2 excels in scenarios where camera setups vary, calibration is unavailable, or deployment environments are unpredictable:
- Autonomous systems operating across cities, warehouses, and rural areas without retraining.
- Consumer AR/VR apps that must work on mobile phones with unknown or varying camera parameters.
- 3D content creation from internet photos or user-uploaded images lacking metadata.
- Academic research requiring a single, strong baseline for cross-dataset depth evaluation.
- Robotics navigation in unmapped or dynamically changing environments where re-calibration isn’t feasible.
Because it doesn’t rely on domain-specific fine-tuning, UniDepthV2 reduces engineering overhead and accelerates time-to-deployment.
Getting Started: Minimal Setup, Maximum Output
Installation is straightforward on Linux with Python 3.10+ and CUDA 11.8+. The package installs via pip with PyTorch support, and a demo script (scripts/demo.py) validates the setup in seconds.
Once installed, users can:
- Load models from Hugging Face or TorchHub.
- Run inference on any RGB image (C×H×W tensor).
- Receive not just depth, but a full 3D point cloud in camera coordinates, predicted intrinsics, and an uncertainty map.
The codebase also supports custom training, with clear guidelines for data normalization, resizing, and camera parameter handling.
Limitations and Practical Considerations
While UniDepthV2 sets a new bar for zero-shot MMDE, users should note:
- License: Released under CC BY-NC 4.0, meaning non-commercial use only. Commercial applications require separate permission.
- Hardware: Optimized for CUDA-enabled GPUs; CPU inference is possible but slower.
- Camera support: While it handles pinhole and fisheye models, extreme optical distortions outside the training distribution may reduce accuracy.
- Edge cases: Performance may dip on highly textureless surfaces or scenes with severe motion blur—common challenges in monocular depth estimation.
That said, its robustness across standard benchmarks and real-world footage makes it one of the most practical MMDE models available today.
Summary
UniDepthV2 redefines what’s possible in universal monocular metric depth estimation. By combining zero-shot generalization, intrinsic-free inference, uncertainty awareness, and developer-friendly deployment, it solves the core pain point that has limited MMDE adoption: fragility outside training domains. For technical leads, researchers, and engineers evaluating depth estimation solutions, UniDepthV2 offers a rare blend of accuracy, flexibility, and simplicity—making it a compelling choice for real-world 3D vision systems.