In the world of on-device computer vision, the tension between speed and accuracy has long defined what’s possible. Engineers building mobile apps, AR experiences, or edge AI systems often face a tough trade-off: use lightweight CNNs like MobileNetV3 for speed but sacrifice accuracy, or adopt lightweight Vision Transformers (ViTs) for better performance at the cost of higher latency and memory usage due to attention mechanisms.
Enter RepViT—a breakthrough architecture that reimagines mobile CNNs through the lens of modern Vision Transformers, delivering state-of-the-art accuracy with record-breaking inference speed on real mobile hardware. Built as a pure convolutional network, RepViT ditches self-attention entirely yet achieves performance that surpasses even the best lightweight ViTs. On an iPhone 12, RepViT hits over 80% top-1 accuracy on ImageNet with just 1.0 ms latency—a milestone no lightweight model had reached before.
For technical decision-makers, product teams, and mobile ML engineers, RepViT offers a compelling path to deploy high-performance vision models without the overhead of transformers—making real-time, on-device intelligence not just feasible, but practical.
Why RepViT? Bridging the ViT-CNN Divide for Mobile
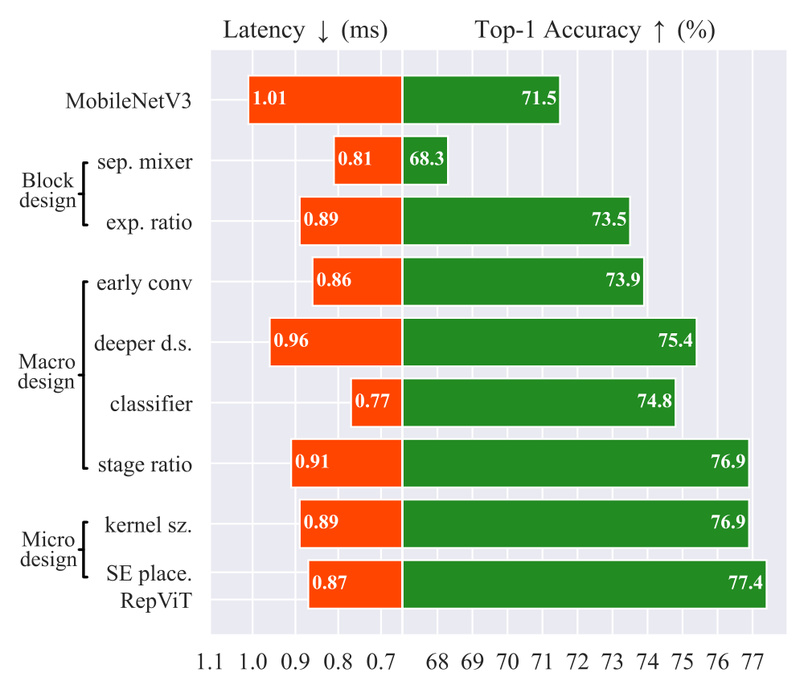
RepViT doesn’t try to replace ViTs—it learns from them. The core insight of the RepViT paper is that many architectural choices in successful lightweight ViTs (like token mixing strategies, macro design patterns, and stage-wise scaling) can be translated into CNN-friendly operations without invoking attention.
Starting from MobileNetV3, the authors incrementally integrate ViT-inspired optimizations—such as alternating between 3×3 convolutions and 1×1 pointwise convolutions in a structured block, and rethinking stage transitions—resulting in a pure CNN that behaves like a ViT in efficiency but runs like a classic mobile network in deployment.
This hybrid philosophy gives RepViT a unique edge: it captures the representational power of ViT-style designs while maintaining the hardware-friendly, cache-efficient, and memory-light characteristics of traditional CNNs.
Key Strengths That Matter for Real Products
1. Pure CNN, Zero Attention
Unlike MobileViT or TinyViT, RepViT contains no self-attention layers. This eliminates the quadratic memory complexity and unpredictable runtime spikes common in transformer-based mobile models—making it far more stable and predictable on constrained devices.
2. Unmatched Speed-Accuracy Trade-off
RepViT models (M0.9 through M2.3) offer a scalable family of options:
- RepViT-M1.0: 80.0% ImageNet top-1 accuracy @ 1.0 ms on iPhone 12
- RepViT-M2.3: 83.7% accuracy @ 2.3 ms
These numbers aren’t synthetic—they’re measured using Apple’s Core ML benchmarking tools on a real iPhone 12 running iOS 16.
3. Seamless iOS Deployment
With official support for Core ML export, RepViT integrates smoothly into iOS apps. A single script converts PyTorch checkpoints into optimized Core ML models ready for production.
4. Plug-and-Play via TIMM
RepViT is already integrated into the popular timm (PyTorch Image Models) library, so you can load pretrained models with one line:
from timm.models import create_model
model = create_model('repvit_m1_0', pretrained=True)
Ideal Use Cases: Where RepViT Excels
RepViT is purpose-built for latency-sensitive, on-device vision tasks, including:
- Real-time image classification in camera apps or assistive technologies
- Mobile AR/VR pipelines requiring consistent frame rates
- On-device instance segmentation via RepViT-SAM—a drop-in replacement for MobileSAM that runs 10× faster while improving zero-shot transfer performance
- Edge robotics or IoT vision systems where memory and power budgets are tight
Because it avoids attention mechanisms, RepViT also sidesteps issues like attention map fragmentation or inconsistent kernel launches on mobile GPUs—leading to smoother, more reliable performance in production.
Getting Started: From Evaluation to Deployment
The RepViT repository provides everything needed to evaluate, train, or deploy:
Load & Test Pretrained Models
Use timm or the official checkpoints to immediately run inference on ImageNet or your own data. Evaluation is as simple as:
python main.py --eval --model repvit_m1_0 --resume pretrain/repvit_m1_0_distill_300e.pth --data-path ~/imagenet
Train Custom Variants
RepViT supports distributed training on ImageNet with standard PyTorch tooling—just specify your model size and data path.
Export to Core ML for iOS
Convert models for mobile deployment with:
python export_coreml.py --model repvit_m1_0 --ckpt pretrain/repvit_m1_0_distill_300e.pth
Measure Real Latency
Validate on-device speed using Apple’s Xcode benchmarking tools—the same method used in the paper.
This streamlined workflow means teams can go from proof-of-concept to production without deep expertise in neural architecture design.
Limitations & Practical Considerations
While RepViT sets a new bar for mobile efficiency, it’s not a universal solution:
- Target platform matters: RepViT is optimized for mobile and edge devices. It won’t outperform large server-scale ViTs (like ViT-L) on cloud GPUs where accuracy—not latency—is the priority.
- Training requires standard setup: Like most vision models, RepViT assumes access to ImageNet-style datasets and multi-GPU training infrastructure for full fine-tuning.
- iOS deployment dependency: Core ML export is well-supported, but Android users must rely on other conversion paths (e.g., ONNX + TensorFlow Lite), which may require additional validation.
How RepViT Compares to Alternatives
| Model | Architecture | ImageNet Acc. | iPhone 12 Latency | Attention? |
|---|---|---|---|---|
| MobileNetV3 | CNN | ~75% | ~1.0 ms | No |
| MobileViT | CNN + ViT hybrid | ~78% | ~2.5 ms | Yes |
| TinyViT | ViT | ~79% | ~1.8 ms | Yes |
| RepViT-M1.0 | Pure CNN | 80.0% | 1.0 ms | No |
Moreover, RepViT-SAM directly addresses the limitations of MobileSAM, which relies on TinyViT’s attention-heavy encoder. By swapping in RepViT, segmentation becomes dramatically faster—enabling real-time “Segment Anything” on phones for the first time.
Summary
RepViT redefines what’s possible for lightweight vision models by proving that you don’t need transformers to get transformer-level performance on mobile. With its pure CNN design, ViT-inspired optimizations, and real-world speed records, it offers a practical, deployable, and scalable solution for engineers building the next generation of on-device AI.
If your project demands low latency, low memory, and high accuracy on mobile hardware—without the complexity of attention—RepViT deserves a serious look.