Reinforcement learning (RL) for real-time strategy (RTS) games has long been bottlenecked by slow simulation, rigid environment interfaces, and high hardware demands. Enter ELF—an open-source research platform developed by Facebook AI (now Meta) that directly tackles these pain points. Built for speed and flexibility, ELF enables researchers and engineers to train end-to-end RTS agents in under a day using just 6 CPUs and 1 GPU, thanks to its highly optimized C++ core and seamless Python integration.
At its heart, ELF provides a miniature RTS environment called MiniRTS, which distills the core mechanics of complex games like StarCraft—resource gathering, base building, unit production, exploration, and combat—into a lightweight simulation that runs at 40,000 frames per second per core on a standard laptop. This blistering speed makes on-policy RL methods like A3C not only feasible but efficient, dramatically shrinking iteration cycles and infrastructure costs.
Unlike traditional frameworks such as OpenAI Gym (which wraps one game instance per Python process), ELF batches thousands of concurrent game environments and delivers them as a single tensor-friendly batch to your PyTorch model. This design aligns perfectly with modern deep RL pipelines and removes the engineering overhead of managing multiprocessing or threading manually.
Whether you’re prototyping novel RL algorithms, benchmarking agent performance across game variants, or integrating legacy C++ simulators into a trainable loop, ELF offers a unified, extensible foundation that “just works” out of the box.
Why ELF Solves Real Bottlenecks in Game AI Development
Traditional game AI research often stalls not because of algorithmic limitations, but due to simulation throughput. Most RL methods require millions of environment steps—but if your game runs at 100 FPS across 16 cores, you’re still waiting days for meaningful signal. ELF flips this script.
By running 1,024 MiniRTS games in parallel and delivering state batches directly to PyTorch, ELF ensures your GPU isn’t idling while waiting for data. The result? A full-game bot that defeats rule-based opponents over 70% of the time can be trained from scratch in less than 12 hours on modest hardware.
Moreover, ELF’s flexible agent-environment topology supports diverse research scenarios:
- Batched A3C: One neural network processes actions for hundreds of games simultaneously.
- Self-play: Pit two evolving agents against each other for emergent strategy discovery.
- Multi-agent setups: Explore cooperation or competition with custom agent configurations.
This flexibility, combined with raw speed, removes the “glue code” burden that often distracts researchers from their core hypotheses.
Key Strengths That Set ELF Apart
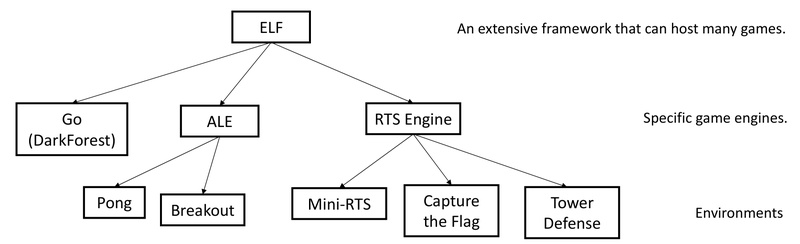
Extensive: Plug In Any C/C++ Environment
ELF isn’t limited to MiniRTS. Its architecture welcomes any game engine with a C/C++ interface. The platform already includes working integrations for:
- Arcade Learning Environment (Atari): Run 1,000+ Atari ROMs concurrently with minimal overhead.
- Go: A reimplementation of the DarkForest Go engine, enabling lightweight training from SGF files.
- Custom RTS variants: Modify win conditions, unit stats, or map layouts via simple configuration.
Adding a new environment requires only a lightweight wrapper—no need to rebuild the entire concurrency backend.
Lightweight: Blazing-Fast Simulation with Minimal Overhead
Built on C++11 and Intel TBB for thread management, ELF achieves near-linear scaling across CPU cores. The MiniRTS engine—written specifically for research—omits graphical rendering and focuses purely on game logic, enabling 40K FPS per core. This efficiency translates directly into faster training: experiments that once required a GPU cluster can now run on a single workstation.
Flexible: Match Your Algorithm to Your Experiment
ELF decouples environment execution from agent logic. You decide how agents interact with games:
- One agent per environment (classic RL)
- One agent for many environments (data-parallel training)
- Many agents per environment (multi-agent or self-play)
The Python API is intentionally minimal—just define your input and reply specs, and ELF handles batching, synchronization, and communication via ZeroMQ (for multiprocessing) or direct C++ threading.
Practical Use Cases Where ELF Shines
ELF excels in scenarios where speed, control, and scalability are critical:
- End-to-end RTS bot development: Train agents that perceive raw game state and output build/attack/move commands without handcrafted features.
- Large-scale RL hyperparameter sweeps: Launch hundreds of concurrent training runs with varied curricula, horizons (e.g.,
--T 20), or opponent types. - Game design prototyping: Tweak MiniRTS mechanics—like resource rates or fog-of-war visibility—and immediately observe how agents adapt.
- Legacy simulator modernization: Wrap existing C++ game engines (e.g., custom tactical simulators) into a PyTorch-native training loop without rewriting core logic.
The included train_minirts.sh and eval.py scripts demonstrate how to go from code checkout to a competitive agent in under an hour.
Getting Started with ELF: A Developer-Friendly Workflow
Adopting ELF requires standard research-stack tools but delivers immediate returns:
- Install dependencies: CMake ≥3.8, GCC ≥4.9,
libtbb-dev, Python 3, PyTorch, andmsgpack_numpy. - Build the RTS engine: A simple
cmake+makesequence compiles the core simulator. - Launch training: Run
./train_minirts.sh --gpu 0to start end-to-end learning against built-in AIs. - Evaluate and visualize: Use
eval.py --greedy --save_replay_prefix my_gameto generate replays, then inspect strategies via the built-in web UI (rts/frontend/minirts.html).
The platform’s design ensures that even first-time users can reproduce the paper’s 70%+ win rate against AI_SIMPLE within a day—no distributed infrastructure needed.
Limitations and Practical Considerations
While powerful, ELF is optimized for research, not production deployment. Key considerations include:
- Hardware/toolchain requirements: A C++11-compatible build environment is mandatory; Windows support is limited.
- Learning curve: Users should be comfortable with PyTorch and basic RL concepts (e.g., advantage estimation, policy gradients) to customize training.
- Simplified environments: MiniRTS captures RTS dynamics but lacks the complexity of commercial titles like StarCraft II. It’s a testbed, not a replacement.
- Maintenance status: As an archived Meta research project (last major update in 2017), ELF won’t receive new features—but its core design remains robust for foundational experiments.
That said, for teams focused on algorithmic innovation rather than AAA game integration, these trade-offs are more than acceptable.
Summary
ELF redefines what’s possible in game-based reinforcement learning by removing the traditional bottlenecks of speed, rigidity, and complexity. With its unique blend of high-throughput simulation, clean Python APIs, and support for diverse RL paradigms, it empowers researchers to iterate faster, experiment more boldly, and ship results sooner. If you’re building or evaluating agents for strategy games—or any fast, state-rich environment—ELF isn’t just a tool; it’s a force multiplier.