Traditional multimodal large language models (MLLMs) often produce answers without revealing how they got there—especially when dealing with complex questions that combine images and text. This “black-box” behavior makes them risky for applications where traceability, debuggability, and correctness matter, such as in medical imaging, engineering diagnostics, or educational tools.
Enter Mulberry: a new generation of MLLM explicitly designed to reason like OpenAI’s o1—step by step, with reflection, and full transparency. Built on a novel method called Collective Monte Carlo Tree Search (CoMCTS), Mulberry doesn’t just guess the answer. It constructs a searchable tree of reasoning steps, validates them through collaborative model feedback, and learns from high-quality, human-aligned paths. The result? A model that doesn’t just answer—it explains, reflects, and improves.
For technical decision-makers evaluating next-generation multimodal systems, Mulberry offers a rare combination: strong performance on benchmarks, full reasoning traceability, and an open, modular toolchain ready for integration.
Why Step-by-Step Reasoning Matters in Multimodal AI
Most MLLMs today are trained to predict final answers directly from image-text inputs. While this works for simple queries (“What color is the car?”), it fails for layered problems (“Given this circuit diagram, why is the output voltage dropping under load?”). Without intermediate reasoning, errors are undetectable, debugging is impossible, and trust is low.
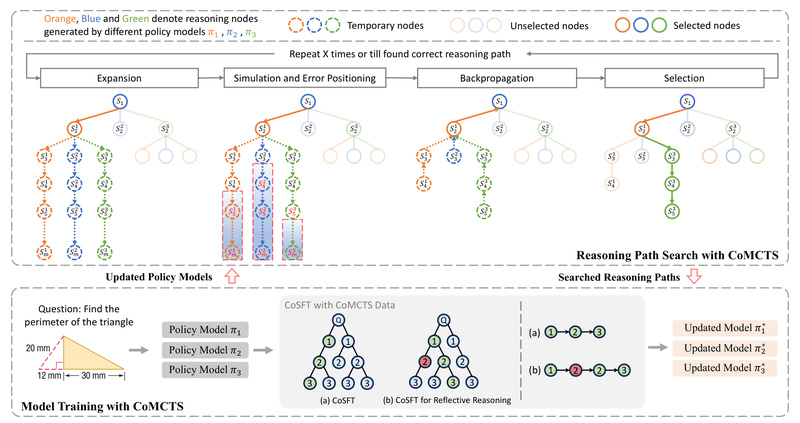
Mulberry addresses this by treating reasoning as a search problem. Instead of a single linear path, it explores multiple plausible reasoning trajectories using CoMCTS—a process inspired by game-tree search but enhanced with collective intelligence from multiple models. This collaborative approach:
- Identifies promising reasoning steps,
- Detects and localizes errors in intermediate logic,
- Refines paths through iterative simulation and backpropagation,
- And ultimately selects high-fidelity chains that lead to correct answers.
The outcome is Mulberry-260k, a dataset of 260,000 multimodal questions, each annotated with explicit, tree-structured reasoning—perfect for supervised fine-tuning of transparent, reflective MLLMs.
Key Capabilities That Make Mulberry Stand Out
1. o1-Like Reasoning and Reflection
Mulberry doesn’t just “think”—it shows its work. When queried, it generates a sequence of logical steps, self-checks for inconsistencies, and revises flawed reasoning. This mirrors the reflective cognition seen in OpenAI’s o1, but now in an open, multimodal context.
2. Collective Monte Carlo Tree Search (CoMCTS)
CoMCTS is the engine behind Mulberry’s data generation and reasoning quality. By coordinating multiple models (e.g., GPT-4o, Qwen2-VL, LLaMA-Vision), it cross-validates each reasoning node. This collective verification dramatically boosts the success rate of finding correct reasoning paths—far beyond what any single model can achieve alone.
3. Ready-to-Use Models and Full Toolchain
The project ships with production-ready models:
- Mulberry-LLaVA-8B
- Mulberry-Qwen2VL-7B
- Mulberry-LLaMA-Vision-11B
Each supports two inference modes:
- Full reasoning trace (for debugging and transparency)
- Final answer only (for latency-sensitive deployments)
All code—including CoMCTS data generation, supervised fine-tuning via LLaMA-Factory, and benchmark evaluation through VLMEvalKit—is open-sourced and well-documented.
Ideal Use Cases: Where Mulberry Delivers Real Value
Mulberry shines wherever how you got the answer is as critical as the answer itself:
- Education: AI tutors that show step-by-step solutions to visual math or science problems, enabling students to learn from the reasoning process.
- Technical Diagnostics: Analyzing schematics, medical scans, or engineering drawings with auditable logic trails.
- Robotics & Autonomous Systems: Making perception decisions that can be inspected and validated by safety engineers.
- Research & Development: Reproducible multimodal reasoning for scientific discovery or data analysis workflows.
In short, if your application demands explainability, verifiability, or error analysis, Mulberry is purpose-built for you.
Getting Started: A Practical Workflow for Engineers
Adopting Mulberry requires no deep expertise in tree search algorithms—just standard MLLM integration skills:
-
Run inference with one command:
python infer.py --model 'Mulberry_llava_8b' --model_path 'HuanjinYao/Mulberry_llava_8b' --question 'Question: <Your_Question>' --img_path '<Your_Img_Path>'
Add
--only_output_final_answerto skip reasoning traces. -
Fine-tune using the Mulberry-260K dataset and LLaMA-Factory—just register the dataset in
dataset_info.jsonand launch training with a YAML config. -
Evaluate on standard benchmarks (e.g., MathVista, MMMU) using the patched VLMEvalKit, ensuring apples-to-apples comparisons with other MLLMs.
Everything is modular, container-friendly, and designed for technical teams to plug into existing pipelines.
Known Limitations: What to Watch For
The Mulberry team is transparent about current constraints:
- Hallucinations in intermediate steps: Even when the final answer is correct, some reasoning nodes may contain factual errors. This is a known challenge in MLLMs generally, and while CoMCTS mitigates it via multi-model verification, it doesn’t eliminate it entirely.
- Error localization sensitivity: Smaller models used in CoMCTS may struggle to pinpoint where a reasoning path went wrong. The authors recommend using larger models (e.g., GPT-4o, Qwen2-VL-72B) for error checking or refining prompts to boost smaller models’ diagnostic ability.
These aren’t blockers—but considerations for high-stakes deployments. For most technical applications, however, Mulberry’s reasoning transparency already represents a major leap forward.
Summary
Mulberry redefines what’s possible in multimodal reasoning by combining o1-style step-by-step reflection with a scalable, open-source framework. It solves a critical pain point: the opacity of traditional MLLMs. With its CoMCTS-powered data generation, ready-to-deploy models, and full development toolchain, it empowers technical teams to build AI systems that are not only accurate—but also trustworthy, debuggable, and auditable.
If your project demands more than just answers—if it needs reasons—Mulberry is a compelling choice worth evaluating today.