Online fashion retailers, digital content studios, and marketing teams increasingly rely on realistic human imagery to showcase garments—but traditional virtual try-on (VTON) systems fall short when flexibility is required. Most existing solutions fix the human subject and only swap garments onto a pre-captured person, offering little to no control over pose, facial identity, background scene, or artistic style. This lack of compositional freedom limits scalability and creativity, especially for merchants who need to present the same clothing item across diverse contexts without conducting repeated photoshoots.
Enter IMAGDressing-v1, a novel framework that redefines the problem as Virtual Dressing (VD)—a broader, more versatile task focused on generating fully editable human images while preserving garment fidelity. Unlike conventional VTON methods, IMAGDressing allows users to freely specify (or randomize) the face, pose, text-driven scene, and even visual style—all while keeping the input garment intact and realistically rendered. Built on Stable Diffusion and enhanced with modular plugins like ControlNet and IP-Adapter, IMAGDressing delivers state-of-the-art results without requiring LoRA fine-tuning or per-garment model retraining.
Why IMAGDressing Solves Real Workflow Pain Points
Traditional virtual try-on tools prioritize consumer-facing “try-before-you-buy” experiences. But for businesses and creators, the real need lies in efficiently producing varied, high-quality visuals of the same garment—worn by different models, in different poses, against different backgrounds. This is critical for:
- E-commerce platforms that want to display thousands of SKUs with diverse model representations without incurring massive photography costs.
- Fashion designers iterating on how a single outfit appears across body types or motion states.
- Digital artists and animators who require stylized (e.g., cartoon) avatars dressed in real-world clothing references.
- Marketing teams prototyping ad campaigns with dynamic scene control (“a model wearing this dress on a beach at sunset”).
IMAGDressing directly addresses these needs by decoupling garment representation from human identity and context—enabling controlled composition rather than passive overlay.
Core Technical Innovations
At its heart, IMAGDressing-v1 introduces two key components:
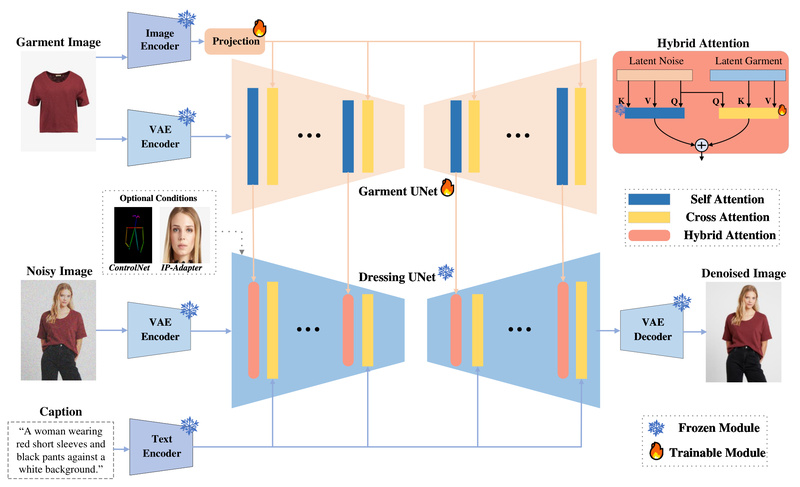
A Dedicated Garment UNet
This module extracts both semantic features (via CLIP) and texture details (via VAE) from the input garment image. By encoding garment structure and appearance separately, the system preserves critical visual properties like fabric pattern, stitching, and drape—essential for commercial realism.
Hybrid Attention Integration
To inject garment features into the image generation process, IMAGDressing employs a frozen self-attention (to maintain stability in the base diffusion model) and a trainable cross-attention mechanism that fuses garment information into the denoising UNet. This design ensures that text prompts (e.g., “in a snowy mountain”) or pose controls (via OpenPose) don’t distort the core garment identity.
Critically, the base denoising UNet remains frozen—meaning users get rapid customization in seconds, with no need for per-outfit fine-tuning or LoRA training.
Plug-and-Play Compatibility with Popular SD Ecosystems
IMAGDressing isn’t a siloed tool—it’s designed to work seamlessly within existing Stable Diffusion workflows. It natively supports integration with:
- ControlNet (for pose, depth, or edge control)
- IP-Adapter (to condition on a specific face or identity)
- T2I-Adapter (for additional spatial guidance)
- AnimateDiff (future video dressing support is planned)
This modularity allows technical teams to combine IMAGDressing with their existing pipelines—whether for batch generation, UI deployment, or research experimentation.
Practical Use Cases for Teams
Rapid Garment Visualization
Upload a single product photo of a dress or shirt, and instantly generate images of it worn by models in standing, walking, or sitting poses—without capturing any human subject.
Cross-Style Rendering
Use the experimental cartoon-style mode to generate anime or illustrative avatars dressed in real-world fashion items—ideal for gaming, virtual influencers, or NFT collections.
Localized Outfit Editing
The inpainting feature (currently experimental) allows users to replace only a portion of clothing on an existing person—for example, swapping a T-shirt while keeping pants and shoes unchanged.
Batch Production for E-Commerce
With command-line support for batch inference, teams can automate the generation of hundreds of model-garment combinations using scripts—dramatically reducing manual production time.
Getting Started Without Deep ML Expertise
IMAGDressing prioritizes usability. After setting up a standard Python/PyTorch environment (≥3.8, CUDA 11.8), users can:
-
Run one-line inference commands to generate images with random or specified conditions:
python inference_IMAGdressing.py --cloth_path ./dress.jpg→ random face/posepython inference_IMAGdressing_controlnetpose.py --cloth_path ./dress.jpg --pose_path ./pose.png→ fixed posepython inference_IMAGdressing_ipa_controlnetpose.py --cloth_path ./dress.jpg --face_path ./face.jpg --pose_path ./pose.png→ fixed face + pose
-
Use the Gradio web interface (
app.py) for a no-code, browser-based experience—ideal for designers or product managers.
Pre-trained models (e.g., Realistic Vision V4.0) and garment encoders are available on Hugging Face, and the required dependencies are clearly documented.
Built-In Evaluation: The CAMI Metric
Unlike many generative tools that offer no objective quality measure, IMAGDressing introduces the Comprehensive Affinity Metric Index (CAMI)—a quantitative score that evaluates how faithfully the generated image preserves the input garment’s appearance.
- CAMI-U: For uncontrolled generation (no face/pose specified)
- CAMI-S: For controlled generation (with identity, pose, and text)
By segmenting the garment region (using tools like Self-Correction Human Parsing) and comparing feature alignment between input and output, teams can objectively validate output quality—a crucial step before deploying in production.
Limitations and Considerations
While powerful, IMAGDressing has current constraints worth noting:
- Licensing: Officially released model checkpoints are for non-commercial research only. Commercial use requires separate licensing or retraining.
- Resolution: The publicly available model generates 512×512 images; higher-resolution versions are planned but not yet released.
- Experimental Features: Inpainting-based outfit changes and cartoon-style generation require additional model downloads (e.g., human parsing networks) and may be less stable.
- Garment Quality Dependency: Results are sensitive to input garment clarity—cropped, front-facing, well-lit garment photos yield best outcomes.
Summary
IMAGDressing-v1 fills a critical gap between consumer-focused virtual try-on and enterprise-grade virtual dressing. By enabling fast, controllable, and evaluation-ready human image synthesis with fixed garments, it empowers e-commerce, creative, and research teams to scale visual content production without sacrificing fidelity. With no retraining needed, strong plugin compatibility, and a novel evaluation metric, IMAGDressing stands out as a practical, forward-looking solution for anyone who needs to dress virtual humans—on their own terms.