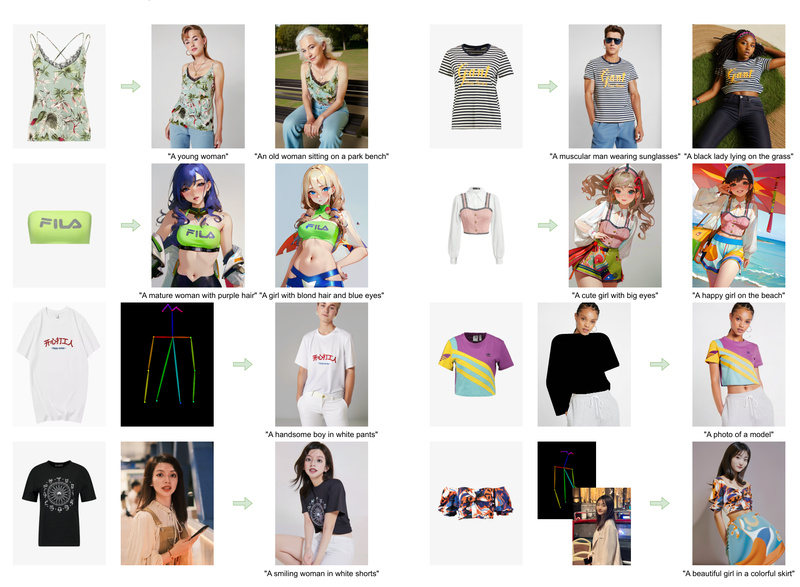
Magic Clothing is a cutting-edge solution for a long-standing challenge in AI-powered visual content creation: how to generate realistic human images that faithfully wear a user-provided garment while still responding accurately to natural language prompts. Built on top of latent diffusion models (LDMs), Magic Clothing introduces precise control over garment appearance without sacrificing prompt alignment—a combination most existing tools struggle to achieve.
Whether you’re building virtual try-on systems, designing digital avatars, or prototyping fashion concepts, Magic Clothing ensures the texture, style, and structure of your input garment remain intact in the final image, even as you vary poses, backgrounds, or character descriptions through text.
Why Garment-Driven Image Synthesis Needs Better Control
Traditional text-to-image models often distort or ignore fine details of provided reference garments. Even models fine-tuned for fashion tend to reinterpret patterns, colors, or cuts based on their internal priors rather than the actual input. This lack of fidelity makes them unreliable for practical applications like e-commerce, where visual accuracy directly impacts user trust and conversion.
Magic Clothing directly addresses this by decoupling garment representation from the generative process. Instead of relying solely on coarse conditions (e.g., segmentation masks or low-res sketches), it extracts high-fidelity garment features and injects them into the diffusion pipeline in a way that preserves their integrity throughout generation.
Core Innovations That Enable Precision and Flexibility
Garment Extractor: A Plug-and-Play Module for Detail Preservation
At the heart of Magic Clothing is a lightweight, reusable garment extractor. This module captures texture, fabric folds, logos, and other visual details from a single garment image and integrates them into pretrained LDMs through self-attention fusion. Crucially, this design means the extractor doesn’t require retraining the base model—it works as a plug-in compatible with various fine-tuned diffusion checkpoints.
Joint Classifier-Free Guidance for Dual Control
Magic Clothing uses a modified classifier-free guidance strategy that independently balances two signals:
- Garment fidelity: How closely the output matches the input garment’s appearance.
- Text alignment: How well the image reflects the semantic content of the prompt (e.g., “a woman in a red trench coat standing on a rainy street”).
Users can adjust the strength of each signal, enabling scenarios like soft stylization (strong text, moderate garment) or strict replication (strong garment, minimal text interference).
Seamless Integration with Popular Control Extensions
Magic Clothing isn’t limited to garment+text inputs. It natively supports extensions like:
- ControlNet (OpenPose): To enforce specific body poses using a reference skeleton.
- IP-Adapter (FaceID): To preserve facial identity from a portrait image.
This composability makes it ideal for complex workflows—e.g., generating a custom character wearing a designer jacket, matching a celebrity’s face, and striking a runway pose—all from separate, modular inputs.
Practical Applications for Teams and Creators
Virtual Try-On at Scale
E-commerce platforms can generate lifelike try-on images using only a flat garment photo and a base model image, reducing reliance on photoshoots.
AI-Assisted Fashion Design
Designers can explore “what-if” scenarios: “Show this dress on diverse body types in Parisian streetwear style”—all while keeping the original fabric pattern intact.
Game and Media Character Prototyping
Concept artists and indie developers can rapidly iterate character outfits by swapping garment references and adjusting prompts, accelerating pre-production.
Getting Started: Simple Setup, Immediate Results
Magic Clothing ships with everything needed for inference:
- Install dependencies in a Python 3.10 environment with PyTorch 2.0+.
- Download pretrained weights (available for both 512×512 and 768×768 resolutions).
- Run generation via script or Gradio interface:
- Provide a garment image and text prompt.
- Optionally add a pose map (via ControlNet) or face reference (via IP-Adapter).
- Adjust garment and text guidance strengths for desired balance.
No training is required to use the model—only inference code is currently released, which aligns with the needs of most practitioners focused on deployment rather than model development.
Current Limitations and Realistic Expectations
While powerful, Magic Clothing has practical boundaries:
- Training code is not yet public, so custom fine-tuning isn’t possible.
- Garment quality matters: Blurry, wrinkled, or poorly lit inputs reduce output fidelity.
- Assumes standard human form: Extreme body proportions or non-human subjects may lead to misalignment.
- Hardware demands: Like all diffusion models, generation requires a capable GPU and takes seconds per image.
These are typical trade-offs in controllable generation, but the project’s modular design means future integration with faster samplers or quantized models is feasible.
Summary
Magic Clothing solves a specific but critical problem in controllable image synthesis: preserving the exact visual identity of a garment while allowing flexible, text-driven scene composition. Its plug-and-play architecture, support for multi-condition inputs, and tunable guidance make it uniquely suited for real-world applications in fashion tech, digital media, and personalized content generation. For teams needing reliable, detail-accurate outfit visualization without sacrificing creative control, Magic Clothing offers a compelling—and immediately usable—solution.