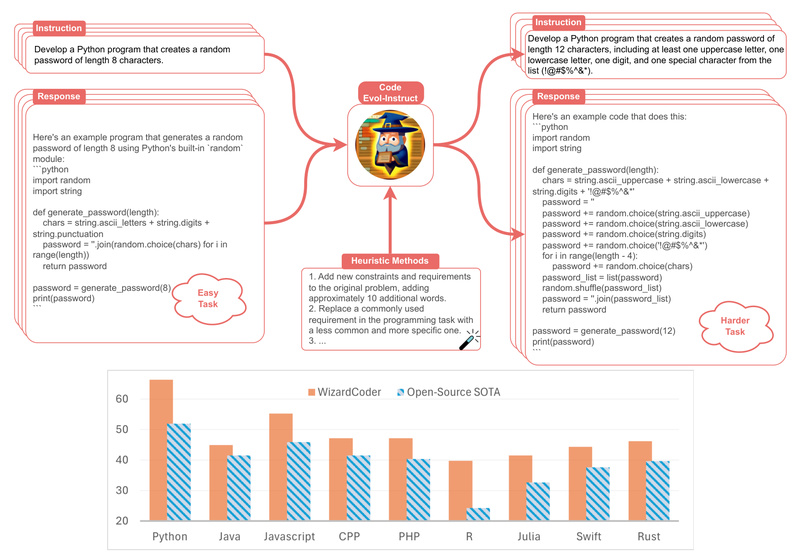
WizardCoder is a state-of-the-art open-source Code Large Language Model (Code LLM) that delivers exceptional performance on code generation tasks—often surpassing well-known commercial models like ChatGPT 3.5, Gemini Pro, and even early versions of GPT-4. Built using the innovative Evol-Instruct fine-tuning method, WizardCoder adapts general-purpose or code-specific base models—such as DeepSeek-Coder—through instruction tuning with synthetic, progressively more complex programming tasks. The result is a family of models that understand nuanced coding instructions, generate reliable and executable code, and are freely available for research and internal development.
Unlike many foundational models trained only on raw code corpora, WizardCoder is explicitly optimized to follow human-like instructions, making it uniquely suited for real-world software engineering workflows where clarity, correctness, and adaptability matter.
Why WizardCoder Stands Out
Benchmark-Leading Performance
WizardCoder consistently sets new records among open-source Code LLMs. For example, WizardCoder-33B-V1.1 achieves:
- 79.9 pass@1 on HumanEval
- 73.2 pass@1 on HumanEval+
- 78.9 pass@1 on MBPP
- 66.9 pass@1 on MBPP+
These scores not only outperform all other open-source models—including DeepSeek-Coder-33B-instruct—but also exceed ChatGPT 3.5, Gemini Pro, and even Claude on key benchmarks like HumanEval and HumanEval+. In coding tasks, this translates to higher accuracy in generating functionally correct code from natural language prompts.
Built for Real Engineering Needs
Many teams face challenges with proprietary coding assistants: unpredictable outputs, API rate limits, data privacy concerns, and lack of control over model updates. WizardCoder addresses these pain points by offering:
- Open weights (hosted on Hugging Face)
- Offline deployment capability
- Reproducible inference with documented prompt templates
- Multiple model sizes (1B, 3B, 7B, 13B, 15B, 33B+) to fit diverse hardware and latency constraints
Whether you’re building an internal code completion tool or automating technical interviews, WizardCoder gives you full ownership of the inference pipeline—without vendor lock-in.
Ideal Use Cases
WizardCoder shines in scenarios that demand instruction-following precision and code correctness. Common applications include:
- IDE-integrated code completion: Suggest entire functions or classes based on docstring-like instructions.
- Automated unit test generation: Create test cases from function specifications.
- Legacy code refactoring: Translate older codebases (e.g., Python 2 to Python 3) or modernize syntax.
- Educational coding assistants: Help students learn by generating illustrative examples or debugging hints.
- Custom coding agents: Serve as the core engine for autonomous programming systems or AI pair programmers.
Because WizardCoder models are open and modular, they can be further fine-tuned on proprietary codebases to specialize in domain-specific languages or internal APIs—something impossible with closed commercial models.
Getting Started Is Straightforward
Using WizardCoder requires no complex setup. The model follows a simple instruction-response prompt format:
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{your coding task here}
### Response:
For example:
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Write a Python function that returns the factorial of a non-negative integer using recursion.
### Response:
def factorial(n):if n < 0:raise ValueError("Input must be non-negative.")if n == 0 or n == 1:return 1return n * factorial(n - 1)
Models are available on Hugging Face under permissive research licenses and can be loaded using standard libraries like Hugging Face Transformers or high-performance servers like vLLM. The official repository (https://github.com/nlpxucan/WizardLM) includes inference scripts (e.g., src/infer_wizardlm13b.py) that ensure outputs match published benchmark results.
Important Limitations to Consider
While powerful, WizardCoder comes with caveats that technical decision-makers must evaluate:
- License restrictions: Most versions are released under research-only or non-commercial licenses (e.g., Llama 2 License). Confirm licensing terms before deployment.
- Language bias: Versions like WizardCoder-Python-34B-V1.0 are heavily optimized for Python. Performance on other languages (e.g., JavaScript, Java) may lag unless using more general variants.
- Training data not public: Due to legal review, the instruction dataset used for Evol-Instruct fine-tuning is not yet released. This limits full reproducibility of the training pipeline—but not inference.
- Size vs. accuracy trade-off: Smaller models (1B, 3B) show significantly lower pass@1 scores and are only suitable for lightweight or edge environments.
Summary
WizardCoder redefines what’s possible with open-source code generation. By combining the Evol-Instruct methodology with strong base models, it delivers performance that rivals or exceeds leading commercial systems—while remaining transparent, inspectable, and controllable. For engineering teams, researchers, and educators seeking a reliable, high-performance coding assistant free from API dependencies or black-box limitations, WizardCoder offers a compelling, production-ready foundation. With multiple model sizes, clear usage patterns, and strong benchmark results, it’s a top contender for any project demanding intelligent, accurate, and auditable code synthesis.