For technical decision-makers evaluating large language models (LLMs) for real-world applications, balancing raw capability, inference cost, training efficiency, and deployment flexibility is a persistent challenge. Enter DeepSeek-V3—a state-of-the-art open-source Mixture-of-Experts (MoE) language model that delivers performance rivaling leading closed-source systems while maintaining remarkable efficiency and accessibility.
With 671 billion total parameters but only 37 billion activated per token, DeepSeek-V3 strikes an intelligent balance between scale and sparsity. Built on innovations validated in DeepSeek-V2—such as Multi-head Latent Attention (MLA) and the DeepSeekMoE architecture—it pushes the frontier of what’s possible in open-source AI without demanding exorbitant computational resources. Trained on 14.8 trillion high-quality tokens, and refined through supervised fine-tuning and reinforcement learning, DeepSeek-V3 is engineered for both strength and stability, completing its full training in just 2.788 million H800 GPU hours—a surprisingly economical figure for its class.
More importantly, DeepSeek-V3 is not just a research artifact; it’s designed for real deployment. With native FP8 support, compatibility across NVIDIA, AMD, and Huawei Ascend hardware, and integrations with leading inference engines like SGLang, vLLM, LMDeploy, and TensorRT-LLM, it empowers engineering teams to bring cutting-edge reasoning, coding, and multilingual capabilities into production quickly and cost-effectively.
Exceptional Performance Across Critical Domains
DeepSeek-V3 doesn’t just scale—it excels where it matters most to technical teams.
Code Generation That Ships
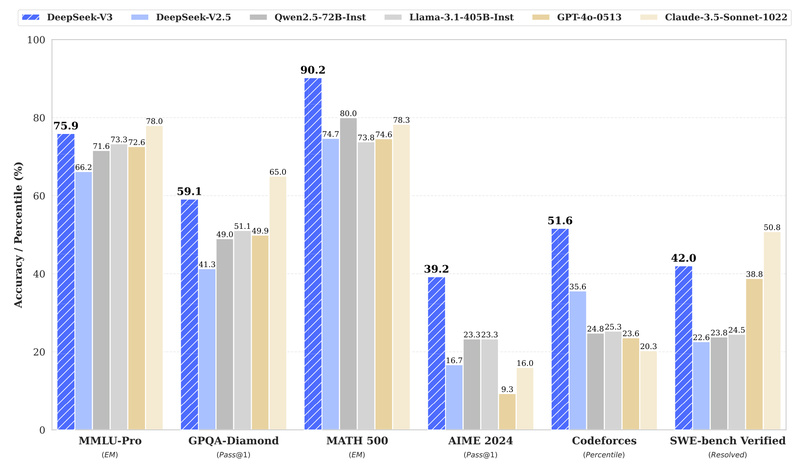
On HumanEval, DeepSeek-V3 achieves a 65.2% Pass@1—significantly outpacing Qwen2.5-72B (53.0%) and LLaMA3.1-405B (54.9%). In more demanding benchmarks like LiveCodeBench-Base, it scores 19.4%, nearly double DeepSeek-V2’s 11.6%. For teams building AI coding assistants, code review tools, or automated debugging systems, this leap translates directly into higher developer productivity and fewer integration bottlenecks.
Mathematical Reasoning That Solves Hard Problems
DeepSeek-V3 dominates math-heavy tasks:
- GSM8K: 89.3% (vs. 88.3% for Qwen2.5)
- MATH: 61.6% (vs. 54.4% for Qwen2.5)
- CMath: a remarkable 90.7%
This makes it ideal for educational platforms, quantitative finance tools, or scientific reasoning agents where precision and step-by-step logic are non-negotiable.
Multilingual and General Knowledge Mastery
DeepSeek-V3 sets new open-source records on C-Eval (90.1%), CMMLU (88.8%), and MMMLU-non-English (79.4%), proving it’s not just an English-first model. Its 128K context window—validated via Needle-in-a-Haystack tests—ensures robust handling of long documents, codebases, or multi-turn conversations without information loss.
In head-to-head comparisons with models like LLaMA3.1-405B and Qwen2.5-72B, DeepSeek-V3 consistently ranks #1 among open-source models and often competes with Claude 3.5 Sonnet and GPT-4o on specialized tasks like DROP (91.6% F1) and AIME 2024 (39.2% Pass@1).
Engineered for Efficiency: Training and Inference Without the Overhead
One of DeepSeek-V3’s greatest strengths is how it achieves top-tier performance without unsustainable costs.
FP8 Mixed-Precision Training at Scale
DeepSeek-V3 pioneers FP8 mixed-precision training for ultra-large MoE models—a first in the open-source ecosystem. This co-design of algorithms, frameworks, and hardware enables near-perfect computation-communication overlap in cross-node training, drastically reducing idle time and accelerating throughput. The result? A 671B-parameter model trained on 14.8T tokens in just 2.664M H800 GPU hours for pre-training—followed by only 0.1M GPU hours for post-training stages.
Stable, Predictable Training
Unlike many large models that suffer from loss spikes requiring rollbacks, DeepSeek-V3’s training was remarkably stable—no irrecoverable failures occurred throughout the entire process. This reliability reduces engineering risk and accelerates iteration cycles for teams running their own fine-tuning pipelines.
Efficient Inference with Low Active Parameters
Despite its massive size, only 37B parameters activate per token—a fraction of dense 405B models. Combined with support for FP8 and BF16 inference, this enables high throughput and low latency on modern GPU clusters, making it viable for latency-sensitive applications like real-time coding assistance or interactive tutoring systems.
Smart Technical Innovations Solving Real Engineering Trade-offs
DeepSeek-V3 introduces two key architectural advances that address longstanding pain points in MoE development.
Auxiliary-Loss-Free Load Balancing
Traditional MoE models use auxiliary losses to encourage balanced expert utilization—but this often harms model performance. DeepSeek-V3 pioneers a loss-free load balancing strategy that maintains high routing efficiency without compromising accuracy or convergence. This means better token distribution across experts and higher task performance—no compromise required.
Multi-Token Prediction (MTP) for Better Learning and Faster Inference
DeepSeek-V3 trains with a Multi-Token Prediction objective, predicting multiple future tokens simultaneously. This not only improves reasoning and coherence during training but also lays the groundwork for speculative decoding during inference—potentially accelerating generation by predicting several tokens in parallel. While MTP support in community inference engines is still under active development, the foundation is already in place for future speedups.
Ready for Production: Flexible Deployment Across Hardware Ecosystems
DeepSeek-V3 is built for the real world—not just research labs.
It is not natively supported by Hugging Face Transformers (yet), but it integrates seamlessly with leading open-source inference frameworks:
- SGLang: Full support for FP8/BF16, MLA optimizations, and AMD/NVIDIA GPU compatibility. Multi-node tensor parallelism enabled.
- vLLM: Supports FP8/BF16 with tensor and pipeline parallelism across networked machines.
- LMDeploy: Optimized for both offline and online serving with FP8/BF16.
- TensorRT-LLM: BF16 and INT4/INT8 quantization available; FP8 support coming soon.
- LightLLM: Efficient single- and multi-node deployment with mixed-precision support.
- AMD GPUs: Day-one FP8/BF16 support via SGLang.
- Huawei Ascend NPUs: BF16/INT8 support through the MindIE framework.
Weights are provided in FP8 format by default (reflecting its training precision), but a simple conversion script (fp8_cast_bf16.py) allows teams to generate BF16 versions for experimentation or compatibility.
Getting started is straightforward: download from Hugging Face, choose your inference backend, and run using provided demos or framework-specific launch scripts—often in under an hour.
Ideal Use Cases for Technical Teams
DeepSeek-V3 shines in scenarios demanding strong reasoning, multilingual support, code intelligence, and long-context understanding:
- AI-powered coding assistants that understand large codebases and generate correct, idiomatic code.
- Multilingual enterprise chatbots for global customer support or internal knowledge retrieval.
- Math and STEM education platforms that provide step-by-step problem solving with high accuracy.
- Research agents that synthesize information from long technical documents or academic papers.
- Custom reasoning engines for finance, legal, or scientific domains—thanks to its Chain-of-Thought distillation from DeepSeek-R1.
With a commercial-friendly license (MIT for code, permissive model license), it’s safe to use in proprietary products without legal ambiguity.
Limitations and Practical Considerations
While powerful, DeepSeek-V3 has a few constraints to consider:
- No native Hugging Face Transformers support—you must use one of the supported inference engines.
- MTP (Multi-Token Prediction) features are still under community development, so speculative decoding isn’t immediately available out-of-the-box.
- FP8 weights require conversion if your pipeline demands BF16.
- Linux-only for the reference demo (Python 3.10), with no official Windows or macOS support.
These are manageable trade-offs for most engineering teams, especially given the model’s performance and ecosystem support.
Summary
DeepSeek-V3 redefines what’s possible in open-source large language models. It combines MoE efficiency, FP8 training innovation, auxiliary-loss-free routing, and multi-token learning to deliver closed-source-tier performance at open-source cost and complexity. With strong results in coding, math, multilingual tasks, and long-context understanding—and broad support across hardware and inference frameworks—it’s one of the most production-ready, high-performance open models available today.
For technical leaders seeking a future-proof, scalable, and commercially viable LLM, DeepSeek-V3 isn’t just an option—it’s a strategic advantage.