In today’s landscape of conversational AI, most voice-enabled systems rely on a pipeline of separate components: automatic speech recognition (ASR) to convert speech to text, a language model to generate a response, and text-to-speech (TTS) to vocalize that response. While functional, this modular approach introduces significant latency, disrupts conversational flow, and increases system complexity—especially for real-time applications like customer service bots, voice assistants, or interactive tutoring tools.
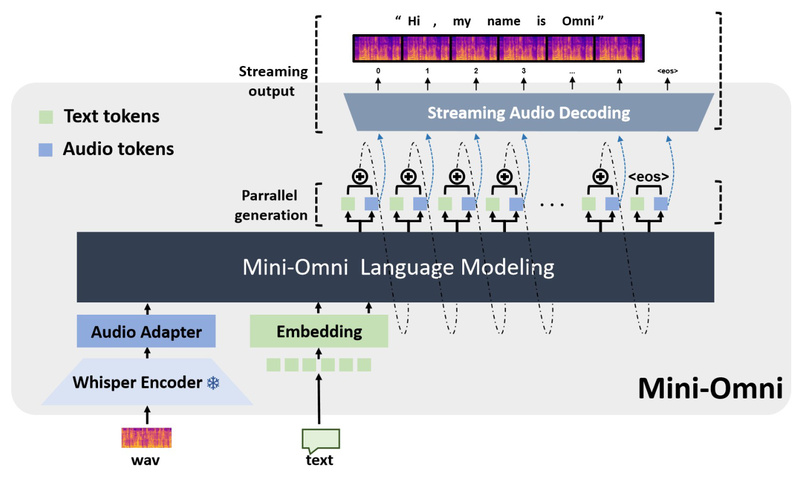
Enter Mini-Omni, the first open-source, end-to-end conversational model that can hear, think, and speak simultaneously in streaming mode—all without external ASR or TTS systems. Built on the Qwen2 language model backbone and enhanced with Whisper for audio encoding and SNAC for decoding, Mini-Omni collapses the traditional voice AI stack into a single, unified architecture. This breakthrough enables near-human fluency in spoken dialogue, making it a compelling choice for technical decision-makers seeking low-latency, integrated voice interaction.
Why Mini-Omni Stands Out
Real-Time Speech-to-Speech in a Single Model
Unlike conventional systems that chain ASR → LLM → TTS, Mini-Omni processes raw audio input and generates streaming audio output directly. This eliminates inter-component handoffs, slashing response time and enabling true real-time conversation. For developers and researchers tired of orchestrating brittle pipelines, this end-to-end design dramatically simplifies deployment and reduces failure points.
“Talking While Thinking” for Natural Interaction
Mini-Omni doesn’t wait to finish reasoning before speaking. Instead, it generates both text and audio in parallel, mimicking how humans often begin speaking before fully formulating a complete thought. This “talking while thinking” behavior—combined with streaming audio output—creates a more natural, responsive conversational experience, crucial for user engagement in applications like virtual assistants or educational agents.
Batch-Parallel Inference for Scalable Performance
To further boost efficiency, Mini-Omni supports batch-parallel inference for both audio-to-text and audio-to-audio tasks. This means multiple user requests can be processed concurrently without degrading latency, making the model more viable for real-world deployments where throughput matters as much as responsiveness.
Practical Use Cases for Technical Teams
Mini-Omni is particularly well-suited for scenarios demanding low-latency, high-fidelity voice interaction without the overhead of managing multiple models:
- Real-time voice assistants for smart devices or enterprise workflows
- Interactive customer support bots that respond conversationally without awkward pauses
- Language learning or tutoring systems where immediate spoken feedback enhances pedagogy
- Research prototypes in human-computer interaction (HCI) exploring natural dialogue dynamics
Because it’s open-source and built on accessible components (Qwen2, Whisper, SNAC), teams can inspect, modify, and integrate Mini-Omni into their own stacks—unlike closed commercial alternatives such as GPT-4o.
Getting Started: A Hands-On Guide
Setting up Mini-Omni is straightforward for those with basic Python and Linux experience:
-
Environment Setup
Create a dedicated Conda environment and install dependencies:conda create -n omni python=3.10 conda activate omni git clone https://github.com/gpt-omni/mini-omni.git cd mini-omni pip install -r requirements.txt
-
Launch the Inference Server
The core model runs as a local API server:sudo apt-get install ffmpeg python3 server.py --ip '0.0.0.0' --port 60808
-
Run a Demo Interface
Choose between two UI options:- Streamlit (requires local PyAudio):
export PYTHONPATH=./ pip install PyAudio==0.2.14 API_URL=http://0.0.0.0:60808/chat streamlit run webui/omni_streamlit.py
- Gradio (simpler setup, slightly higher perceived latency):
API_URL=http://0.0.0.0:60808/chat python3 webui/omni_gradio.py
- Streamlit (requires local PyAudio):
-
Quick Local Validation
Test with preset audio samples using:python inference.py
This workflow allows technical evaluators to assess Mini-Omni’s performance, latency, and voice quality within minutes—critical for rapid prototyping or solution comparison.
Current Limitations to Consider
While Mini-Omni represents a significant leap forward, it’s essential to understand its constraints before committing to a project:
- English-only output: Although the Whisper encoder allows the model to understand multiple languages (including Chinese), all spoken responses are in English. Multilingual output isn’t supported.
- No TTS adapter in open-source release: The internal “post_adapter” (or TTS-adapter) mentioned in the codebase is not included in the public version, limiting customization of voice characteristics.
- Local execution recommended: The Streamlit demo requires PyAudio and must run locally to capture microphone input reliably. Remote browser access may fail due to audio API restrictions.
These limitations mean Mini-Omni is best suited for English-focused, research or prototype-grade applications rather than global, production-scale multilingual services—at least for now.
Summary
Mini-Omni redefines what’s possible in open-source conversational AI by delivering true end-to-end, streaming speech interaction in a single model. By removing dependency on external ASR and TTS systems, it tackles the core pain points of latency and architectural complexity that plague traditional voice pipelines. With features like simultaneous reasoning and speaking, batch-parallel inference, and a straightforward setup process, it empowers technical teams to build more natural, responsive voice applications—today. While currently limited to English output and local deployment scenarios, its open foundation makes it a valuable asset for innovation in real-time spoken dialogue systems.