Multimodal Large Language Models (MLLMs) are transforming how machines understand and reason about visual content. Yet, their adoption remains out of reach for many teams due to massive GPU memory requirements, long inference times, and costly training infrastructure. Enter Bunny—a family of lightweight, open-source MLLMs that proves you don’t need billion-parameter bloat to achieve state-of-the-art results.
Developed by BAAI-DCAI, Bunny leverages a data-centric philosophy: instead of scaling up model size, it scales up data quality. By carefully curating high-value training samples from broad sources like LAION-2B, Bunny trains compact models (as small as 2B–8B parameters) that consistently outperform much larger competitors—including 13B-scale models—on standard multimodal benchmarks.
For engineering teams, researchers, or startups constrained by budget or hardware, Bunny offers a rare combination: top-tier performance, modular flexibility, and deployment-friendly efficiency—all under an open Apache 2.0 license.
Why Bunny Delivers More with Less
Traditional MLLM development follows a “bigger is better” mantra: larger vision towers, wider language backbones, and massive datasets. But this approach demands expensive A100/H100 clusters and weeks of training. Bunny flips the script.
Its core insight—validated in the paper “Efficient Multimodal Learning from Data-centric Perspective”—is that high-quality, de-duplicated, informative training data can compensate for reduced model capacity. Bunny’s training pipeline uses a refined coreset of image-text pairs, filtered to minimize redundancy and maximize semantic diversity. The result? Models like Bunny-4B (based on Phi-3-mini and SigLIP) surpass established 7B and 13B MLLMs across benchmarks like MME, VQA-v2, MMMU, and SEED.
This data-driven efficiency makes Bunny ideal for teams who:
- Operate on modest GPU budgets (e.g., single A10 or consumer-grade RTX cards)
- Need fast inference for real-time applications
- Prioritize rapid iteration over brute-force scaling
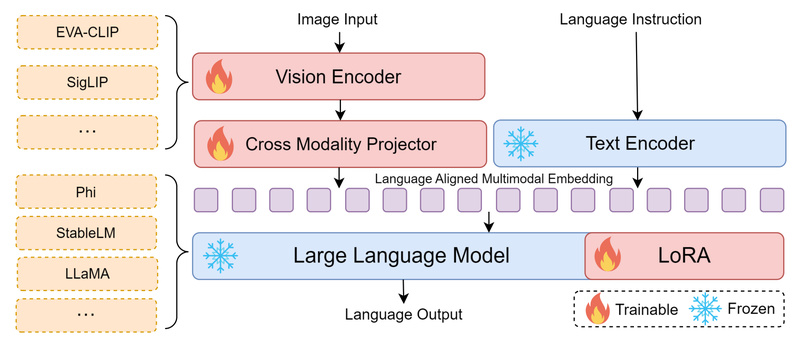
Flexible, Plug-and-Play Architecture
Bunny isn’t a monolithic model—it’s a modular framework that supports interchangeable components. This design enables real-world customization without re-engineering from scratch.
Vision Encoders
Choose between:
- SigLIP (Google’s strong zero-shot vision model)
- EVA-CLIP (high-performance CLIP variant)
Both support high-resolution inputs up to 1152×1152 in v1.1 releases, enabling detailed scene understanding without patching or downscaling.
Language Backbones
Bunny integrates seamlessly with multiple lightweight LLMs:
- Llama-3-8B-Instruct (for general English reasoning)
- Phi-3-mini (ultra-efficient Microsoft model)
- Qwen1.5-1.8B and MiniCPM (for strong Chinese-English bilingual support)
- StableLM-2, Phi-2, and Phi-1.5 (for niche or legacy compatibility)
This flexibility means you can match the language model to your use case—e.g., deploy Bunny-v1.0-2B-zh for Chinese document QA or Bunny-Llama-3-8B-V for complex English visual reasoning—without changing your inference pipeline.
Performance That Defies Size Expectations
Benchmarks don’t lie. On the comprehensive MME (Multi-modal Model Evaluation) suite, Bunny-v1.1-4B scores 1581.5 in perception and 361.1 in cognition—beating many 7B+ models. On MMMU (massive multi-discipline multimodal understanding), it achieves 41.4% accuracy, rivaling models twice its size.
Even more impressively, Bunny-4B matches or exceeds LLaVA-13B—a widely cited baseline—despite using less than one-third the parameters. This performance-per-watt advantage translates directly into lower cloud costs, faster response times, and viability on edge devices.
Getting Started in Minutes
Bunny works out-of-the-box with standard Hugging Face transformers. Here’s a minimal inference example:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from PIL import Image
model = AutoModelForCausalLM.from_pretrained( "BAAI/Bunny-v1_1-4B", torch_dtype=torch.float16, device_map="auto", trust_remote_code=True
)
tokenizer = AutoTokenizer.from_pretrained("BAAI/Bunny-v1_1-4B", trust_remote_code=True)
# Prepare prompt with <image> placeholder
prompt = "Describe this image in detail."
text = f"A chat between a curious user and an AI assistant. USER: <image>n{prompt} ASSISTANT:"
# Tokenize and inject image token (-200)
chunks = [tokenizer(c).input_ids for c in text.split('<image>')]
input_ids = torch.tensor(chunks[0] + [-200] + chunks[1][1:], dtype=torch.long).unsqueeze(0).to("cuda")
# Process image
image = Image.open("example.jpg")
image_tensor = model.process_images([image], model.config).to(dtype=model.dtype, device="cuda")
# Generate response
output = model.generate(input_ids, images=image_tensor, max_new_tokens=100)
print(tokenizer.decode(output[0][input_ids.shape[1]:], skip_special_tokens=True))
For users in regions with Hugging Face access issues (e.g., mainland China), ModelScope support is fully available. Additionally, GGUF-quantized versions enable CPU-only or low-memory inference—ideal for prototyping or resource-limited environments.
Ideal Use Cases
Bunny excels in scenarios where efficiency, cost, and multilingual support matter:
- Edge deployment: Run visual QA on drones, robots, or mobile devices with <16GB RAM
- Rapid prototyping: Test multimodal ideas without waiting for cloud GPU queues
- Cost-sensitive production: Reduce API or inference expenses by 2–5× vs. larger models
- Bilingual applications: Leverage models like Bunny-v1.0-3B-zh for Chinese-English document analysis
- Educational projects: Teach MLLM concepts without requiring institutional-scale compute
Recent extensions like SpatialBot (for depth-aware spatial reasoning) and the MMR benchmark (for robustness testing) further expand Bunny’s applicability to robotics, AR/VR, and safety-critical domains.
Limitations to Consider
Bunny is optimized for vision-language tasks only—it does not natively support audio, video, or sensor fusion. Also:
- Vision and language backbones inherit their original licenses (e.g., Llama-3 requires Meta approval)
- High-resolution (1152×1152) support requires sufficient VRAM (~24GB for 8B models)
- LoRA-based variants require weight merging for standalone deployment (a one-time script is provided)
These are pragmatic trade-offs, not dealbreakers—especially given Bunny’s explicit focus on accessible, efficient multimodal AI.
Extending and Customizing
Bunny isn’t just for inference—it’s built for adaptation. The codebase includes full support for:
- Full fine-tuning and LoRA tuning on custom datasets
- Continuous training on domain-specific data (e.g., medical images, industrial manuals)
- Clear scripts for pretraining and instruction tuning stages
Data formats follow LLaVA conventions, easing migration. With released training data (Bunny-695K) and tutorials, teams can retrain or specialize models in days, not months.
Summary
Bunny redefines what’s possible with lightweight multimodal AI. By prioritizing data quality over model size and offering unmatched architectural flexibility, it delivers performance that rivals or exceeds much heavier systems—while running on accessible hardware. For teams balancing capability, cost, and speed, Bunny isn’t just an alternative; it’s a strategic advantage.
Explore the code, models, and training recipes at github.com/BAAI-DCAI/Bunny—and bring powerful vision-language AI to your project without the computational overhead.