As large language models (LLMs) increasingly power autonomous agents—from customer service bots to system administration tools—a critical question arises: Can this LLM actually function as a reliable agent in real-world tasks? Many models demonstrate impressive conversational ability but falter when required to reason over multiple steps, follow complex instructions, or interact with dynamic environments.
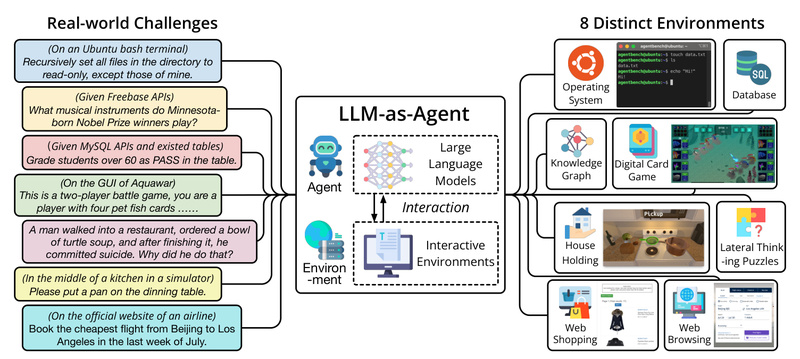
AgentBench directly addresses this gap. Developed by THUDM, it is the first comprehensive benchmark designed specifically to evaluate LLMs as agents—not just as text generators—across eight diverse, interactive environments that mirror real-world scenarios. By providing standardized tasks, containerized execution, and reproducible evaluation metrics, AgentBench empowers technical decision-makers to move beyond marketing claims and assess agent capabilities objectively before committing to a model for their project.
Why AgentBench Matters: From Chatbot to True Agent
Traditional LLM benchmarks focus on static inputs and outputs—question answering, summarization, or code generation. But real agents must act: they navigate operating systems, query databases, manipulate web interfaces, and make sequential decisions based on feedback.
AgentBench shifts the evaluation paradigm by embedding LLMs in simulated but realistic interactive environments. Performance is no longer measured by token accuracy alone, but by whether the agent successfully completes the task—e.g., installing a package via terminal commands, retrieving data from a SQL database, or solving a lateral thinking puzzle through dialogue.
This approach reveals critical gaps: even top open-source models under 70B parameters often struggle with long-horizon planning, instruction fidelity, and state tracking—issues invisible in zero-shot QA benchmarks but fatal in production agent systems.
Eight Environments, One Benchmark
AgentBench includes eight distinct task domains, each reflecting a practical use case for autonomous agents:
- Operating System (OS): Execute commands in a sandboxed Linux environment to achieve goals like file management or software installation.
- Database (DB): Interact with a live MySQL instance to answer natural language queries by writing and executing SQL.
- Knowledge Graph (KG): Query a Freebase-style knowledge base using SPARQL to retrieve structured facts.
- Digital Card Game (DCG): Play strategic card games requiring turn-based reasoning and rule adherence.
- Lateral Thinking Puzzles (LTP): Solve open-ended riddles through iterative questioning and inference.
- House-Holding (HH): Navigate and manipulate a simulated household (via ALFWorld) to complete chores like cleaning or cooking.
- Web Shopping (WS): Browse and purchase items in a simulated e-commerce site (based on WebShop).
- Web Browsing (WB): Perform tasks on real-world websites using actions derived from Mind2Web.
This diversity ensures that models are tested not just on isolated skills, but on their ability to generalize across domains—a key requirement for deployable agents.
AgentBench FC: Function Calling + One-Command Evaluation
The latest version, AgentBench FC (Function Calling), introduces a more practical and developer-friendly evaluation interface. Built on AgentRL—an end-to-end reinforcement learning framework for multi-turn LLM agents—it structures agent interactions as function calls, aligning closely with how real-world applications integrate LLMs (e.g., via tool-use APIs).
Even better: AgentBench FC supports fully containerized deployment via Docker Compose. With a single command, you can spin up all required services for five core tasks: alfworld, dbbench, knowledgegraph, os_interaction, and webshop. This eliminates environment setup headaches and ensures reproducibility across teams and machines.
For example, after building a few Docker images and launching the stack with docker compose -f extra/docker-compose.yml up, your evaluation pipeline is ready—complete with task workers, a central controller, and supporting services like Redis and Freebase.
Getting Started in Minutes
AgentBench is designed for practitioners who want to validate agent performance quickly. Here’s how to run your first evaluation:
- Install dependencies: Clone the repo, create a Python 3.9 environment, and install requirements.
- Configure your LLM: Add your OpenAI API key (or configure another model) in
configs/agents/openai-chat.yaml. - Launch task servers: Run
python -m src.start_task -ato auto-start workers for DB and OS tasks. - Run the evaluation: Execute
python -m src.assignerto begin testing.
Within minutes, you’ll see whether GPT-3.5—or your preferred model—can navigate a terminal, query a database, or complete a web-based purchase. This rapid feedback loop is invaluable for comparing models during technical selection.
What the Results Reveal
Extensive testing across commercial and open-source LLMs shows a stark performance divide. Top-tier commercial models (e.g., GPT-4) demonstrate strong agent capabilities, while most open-source models—even large ones—struggle with:
- Long-term reasoning: Losing track of goals over multiple turns.
- Instruction following: Misinterpreting or ignoring key constraints.
- State awareness: Failing to incorporate environment feedback into subsequent actions.
Interestingly, the paper notes that code training—a common assumption for improving reasoning—has mixed effects: it helps in structured tasks like DB but offers little benefit (or even harm) in open-ended ones like LTP.
These insights help you set realistic expectations and prioritize models based on your domain’s demands.
Practical Constraints to Consider
AgentBench’s realism comes with infrastructure requirements:
- WebShop requires ~16GB RAM per task worker.
- ALFWorld suffers from memory and disk leaks—workers should be restarted periodically.
- Knowledge Graph depends on a local Freebase server; the public endpoint is unstable.
- Ports 5000–5015 must be free (macOS users may need to disable AirPlay).
These are not limitations of AgentBench, but reflections of real-world agent deployment. Understanding them early avoids surprises during integration.
Making Informed Decisions for Your Project
Whether you’re building an IT automation tool, a research assistant, or an e-commerce agent, AgentBench helps you:
- Compare models objectively using task-completion rates, not just perplexity or MMLU scores.
- Identify failure modes specific to your use case (e.g., does your model handle OS commands reliably?).
- Validate custom fine-tuned agents by plugging them into the same evaluation pipeline.
- Benchmark against public leaderboards to contextualize your results.
By grounding agent evaluation in realistic, interactive tasks, AgentBench transforms speculative model selection into evidence-based engineering.
Summary
AgentBench fills a crucial void in the LLM ecosystem: a standardized, multi-environment benchmark that evaluates models not as passive text generators, but as active, decision-making agents. With its diverse task suite, containerized deployment, and actionable insights into model limitations, it equips technical leaders to choose—and deploy—LLM agents with confidence. For anyone considering agents in production systems, AgentBench isn’t just useful—it’s essential.