Deploying large language models (LLMs) at scale in production environments remains a significant challenge for engineering teams. High inference costs, unpredictable latency, inefficient GPU utilization, and the operational complexity of managing dynamic model adaptations like LoRA often hinder the adoption of GenAI in enterprise settings. Enter AIBrix—an open-source, cloud-native framework purpose-built to simplify and optimize large-scale LLM inference.
Developed with a co-design philosophy, AIBrix integrates tightly with leading inference engines like vLLM and leverages Kubernetes and Ray to deliver a production-ready infrastructure stack tailored for real-world GenAI workloads. Whether you’re an engineering leader, platform architect, or DevOps specialist, AIBrix addresses the core pain points of scalable LLM serving while prioritizing cost-efficiency, reliability, and ease of adoption.
Key Challenges in LLM Deployment—and How AIBrix Solves Them
Modern LLM inference pipelines face several recurring bottlenecks:
- Skyrocketing inference costs due to underutilized GPUs and static resource allocation.
- Latency spikes caused by naive load balancing that ignores prompt structure or current node load.
- Operational overhead in managing dozens or hundreds of LoRA adapters for personalized or fine-tuned models.
- Limited token reuse across nodes, leading to redundant computation and wasted resources.
AIBrix tackles each of these issues head-on with infrastructure-level innovations designed specifically for LLMs—not retrofitted from generic cloud patterns.
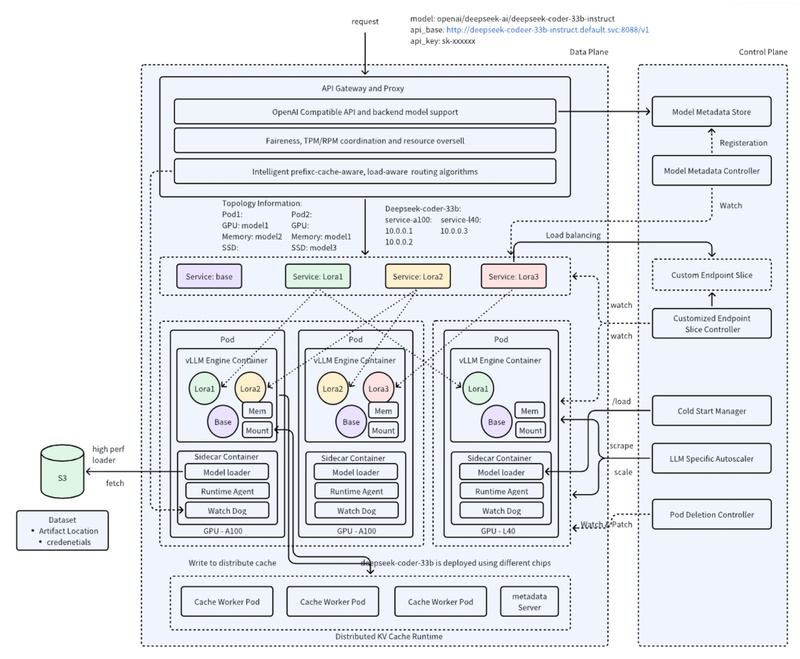
High-Density LoRA Management
AIBrix introduces high-density LoRA management, enabling efficient scheduling and switching of lightweight model adapters without reloading base models. This is critical for multi-tenant platforms or applications requiring real-time personalization, where dozens of LoRA variants may coexist.
LLM-Aware Autoscaling and Routing
Unlike conventional autoscalers that react only to CPU or memory usage, AIBrix employs an LLM-specific autoscaler that monitors queue depth, token generation rates, and service-level objectives (SLOs). Coupled with prefix-aware and load-aware routing, traffic is intelligently directed to replicas that can best reuse cached prompts or handle additional load—dramatically improving throughput and reducing tail latency.
Distributed KV Cache for Cross-Node Token Reuse
One of AIBrix’s most impactful features is its distributed key-value (KV) cache. By enabling token-level caching across multiple nodes, AIBrix achieves up to 50% higher throughput and 70% lower inference latency compared to traditional setups. This is especially valuable for workloads with shared prefixes (e.g., chatbots with system prompts or batched API requests).
Cost-Efficient Heterogeneous Serving
AIBrix supports mixed GPU types (e.g., A100s and H100s in the same cluster) and includes an SLO-driven GPU optimizer that dynamically allocates workloads to the most cost-effective hardware while guaranteeing performance targets. This flexibility allows organizations to maximize ROI on existing infrastructure or take advantage of spot instances without sacrificing reliability.
Architecture Designed for Real-World Adoption
AIBrix adopts a hybrid orchestration model: Kubernetes handles coarse-grained cluster management and scheduling, while Ray manages fine-grained execution tasks such as LoRA switching and KV cache coordination. This split ensures both operational familiarity (for Kubernetes-native teams) and low-latency control (for inference-critical paths).
Additionally, AIBrix provides a unified AI runtime as a sidecar container that standardizes metrics, handles model downloading, and abstracts engine-specific details—allowing seamless integration with vLLM while keeping the system vendor-agnostic for future extensibility.
The framework also includes AI accelerator diagnostic tools that proactively detect GPU failures and support mock-up testing, significantly improving system resilience in production.
Ideal Use Cases
AIBrix excels in environments where scalability, cost control, and operational stability are non-negotiable:
- Enterprise GenAI platforms serving thousands of internal or external users with varying model requirements.
- Multi-tenant LLM hosting where isolated LoRA adapters must be managed efficiently.
- Research labs deploying large models like DeepSeek-R1 that demand reliable, distributed inference infrastructure.
- Cloud-native teams seeking to reduce inference costs by 30–60% without compromising on latency or availability.
Getting Started Is Straightforward
AIBrix is designed for rapid onboarding. You can deploy it on any Kubernetes cluster with just a few commands:
# Install stable v0.5.0 release kubectl apply -f "https://github.com/vllm-project/aibrix/releases/download/v0.5.0/aibrix-dependency-v0.5.0.yaml" --server-side kubectl apply -f "https://github.com/vllm-project/aibrix/releases/download/v0.5.0/aibrix-core-v0.5.0.yaml"
From there, configure your LLM gateway, register models with the unified runtime, and let AIBrix handle scaling, routing, and optimization automatically.
Current Considerations
As of late 2025, AIBrix is at v0.5.0, indicating active development and rapid iteration. While the core features are production-ready, adopters should be comfortable with cloud-native tooling (Kubernetes, Helm, Prometheus) and have basic familiarity with LLM inference concepts.
The framework currently assumes a Kubernetes environment and leverages Ray for intra-cluster coordination—choices that optimize performance but require appropriate operational maturity. Teams without container orchestration experience may need to invest in upskilling before full-scale deployment.
Summary
AIBrix fills a critical gap in the GenAI ecosystem: it provides a purpose-built, open-source infrastructure layer that makes large-scale LLM inference scalable, cost-effective, and operationally manageable. By rethinking every layer—from LoRA scheduling to distributed caching and SLO-aware resource allocation—AIBrix delivers measurable improvements in throughput, latency, and cost efficiency without locking users into proprietary stacks.
For engineering teams looking to deploy production-grade LLM services in 2025 and beyond, AIBrix isn’t just another tool—it’s the foundation for sustainable, enterprise-ready GenAI infrastructure.