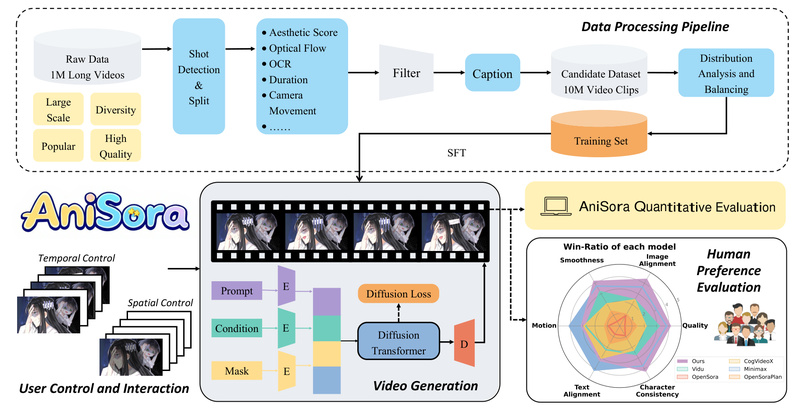
While general-purpose video generation models like Sora, Kling, and CogVideoX have revolutionized photorealistic video synthesis, they consistently underperform when it comes to animation—particularly the highly stylized, physics-defying, and motion-exaggerated aesthetics common in anime, manga, and game (ACG) content. Enter AniSora, a comprehensive open-source system purpose-built for animation video generation. Developed by Bilibili and accepted at IJCAI 2025, AniSora addresses the unique challenges of animated content through a tailored data pipeline, a controllable spatiotemporal generation model, and the first benchmark specifically designed for evaluating anime-style video quality. Licensed under Apache 2.0, the entire project—including model weights, training code, and evaluation tools—is publicly available on GitHub, Hugging Face, and ModelScope.
Unlike models trained on natural-world footage, AniSora is trained on over 10 million high-quality animation frames and optimized for tasks that matter to creators: turning static illustrations into dynamic shots, interpolating keyframes, rotating 2D characters in 3D space, and transferring video styles while preserving character identity. This makes it the only open-source solution today that truly understands the visual grammar of anime.
Why General Video Models Fail on Anime
Animation defies real-world physics by design. Characters stretch, eyes sparkle with impossible reflections, and motion is often symbolic rather than realistic. Standard video diffusion models—trained predominantly on real-world video—struggle with these deviations. They frequently produce inconsistent character appearances across frames, blur stylized linework, or generate motion that feels “too real” and thus visually jarring in an animated context.
AniSora solves this by rethinking the entire pipeline: from data curation to generation architecture and evaluation metrics. Its foundation lies in recognizing that animation is not a “noisy version” of reality but a distinct visual language with its own rules and expectations.
Core Capabilities Designed for Real Animation Workflows
AniSora isn’t just a research prototype—it’s engineered to solve actual production bottlenecks in anime and VTuber content creation. Key features include:
Image-to-Video with Spatial and Temporal Control
Using a novel spatiotemporal mask module, AniSora enables precise control over which parts of a character or scene should move and how. This allows for localized animation guidance—critical when animating only a waving hand or a blinking eye while keeping the rest of the frame static.
Character 3D Rotation from a Single Illustration
Given a front-facing character sheet, AniSora can generate a smooth 360-degree rotation video. This capability supports consistent multi-angle shots without manual redrawing—a major time-saver for storyboarding or 3D asset previsualization.
Arbitrary-Frame Inference
Users can specify any combination of keyframes—first, middle, or last—and AniSora will interpolate the missing frames coherently. This aligns with traditional animation workflows where key poses are defined first.
Multimodal Guidance
Beyond text prompts, AniSora accepts pose maps, depth maps, line art, and even audio as inputs to guide motion. For example, a singing VTuber can be animated by syncing mouth movements to an input audio clip, or a fencing scene can be choreographed using pose skeletons.
Video Style Transfer
By combining line-art extraction with controlled generation, AniSora can transform a live-action or generic animated clip into a specific anime style—preserving motion while altering visual aesthetics.
Ultra-Low-Resolution Video Super-Resolution
AniSora supports efficient generation at 90p and then upscales to 720p or 1080p with enhanced detail. This reduces computational cost during sampling while maintaining final visual quality.
Who Should Use AniSora
AniSora is ideal for:
- Indie animators looking to automate in-between frames or generate motion from manga panels.
- VTuber studios needing consistent, expressive character animations driven by audio or text.
- Anime PV (promotional video) and MAD clip creators who want to remix existing assets into dynamic sequences.
- Researchers in generative AI focusing on stylized video, controllable synthesis, or human preference alignment in non-photorealistic domains.
- Game developers prototyping cutscenes or animated UI elements in 2D styles.
It is not intended for photorealistic video synthesis. Its strength lies exclusively in ACG-style content, where artistic consistency and stylized motion are paramount.
Getting Started: Versions, Hardware, and Ecosystem
AniSora has evolved across three major versions, each optimized for different use cases:
- V1: Built on CogVideoX-5B, suitable for basic image-to-video and localized control. Runs on consumer GPUs like RTX 4090.
- V2: Based on the Wan2.1-14B foundation model, offers distilled, faster inference with native support for Huawei Ascend 910B NPUs. Ideal for cost-efficient deployment.
- V3: The most advanced version, supporting 8-step inference, multimodal guidance, 3D character rotation, and super-resolution. The V3.1 variant runs on GPUs with as little as 12GB VRAM.
All model weights are publicly available on Hugging Face and ModelScope under Apache 2.0. The repository also includes:
- A full data processing pipeline for cleaning and preparing animation datasets.
- An evaluation benchmark with 948 labeled animation clips and specialized metrics for character consistency, motion appeal, and text-video alignment.
- AniSora-RL, the first reinforcement learning from human feedback (RLHF) framework tailored for anime video generation.
To begin, users can download the appropriate version, provide a prompt or conditioning image, and generate short (e.g., 5-second) 360p clips in under 8 seconds on capable hardware.
Limitations and Practical Considerations
While powerful, AniSora has boundaries:
- It currently generates short video clips (typically up to 5 seconds at 360p), not full-length sequences.
- Output quality depends heavily on input quality—blurry or poorly composed reference images may lead to artifacts.
- Motion is intentionally stylized, not physically accurate. This is a feature, not a bug, but users expecting realism should look elsewhere.
- Access to the full evaluation benchmark requires a formal request to the Bilibili team, including institutional affiliation and a handwritten signature, to ensure responsible use.
These constraints reflect the project’s focus: high-fidelity, controllable animation synthesis for creative and research applications—not general-purpose video.
Summary
AniSora is the first open-source, end-to-end system dedicated entirely to animation video generation. By combining a massive curated dataset, a spatiotemporally controllable architecture, and an anime-specific evaluation benchmark, it outperforms general models in character consistency, stylized motion, and creative flexibility. For anyone working in anime, VTuber content, game cinematics, or ACG research, AniSora offers a low-risk, high-reward entry point into automated animation—with full transparency, reproducibility, and community access. In a landscape dominated by black-box video models, AniSora stands out as both technically innovative and practically useful for real-world animation pipelines.