Running large language models (LLMs) used to require powerful GPUs, expensive cloud infrastructure, or specialized hardware—until BitNet changed the game. Developed by Microsoft, BitNet introduces a practical, open-source inference framework called bitnet.cpp that enables fast, lossless, and energy-efficient execution of 1.58-bit LLMs directly on standard CPUs. This means you can run models with billions—even hundreds of billions—of parameters on everyday devices like laptops, edge servers, or mobile hardware, without sacrificing accuracy or relying on cloud APIs.
At its core, BitNet leverages ternary quantization (weights restricted to -1, 0, +1), which reduces model size and enables highly optimized integer-based computations. The result? Dramatic improvements in speed and power efficiency while maintaining full model fidelity—no retraining or accuracy loss required.
Why BitNet Matters for Real-World AI Deployment
Traditional LLM inference is bottlenecked by memory bandwidth, power consumption, and hardware dependency. BitNet directly addresses these pain points:
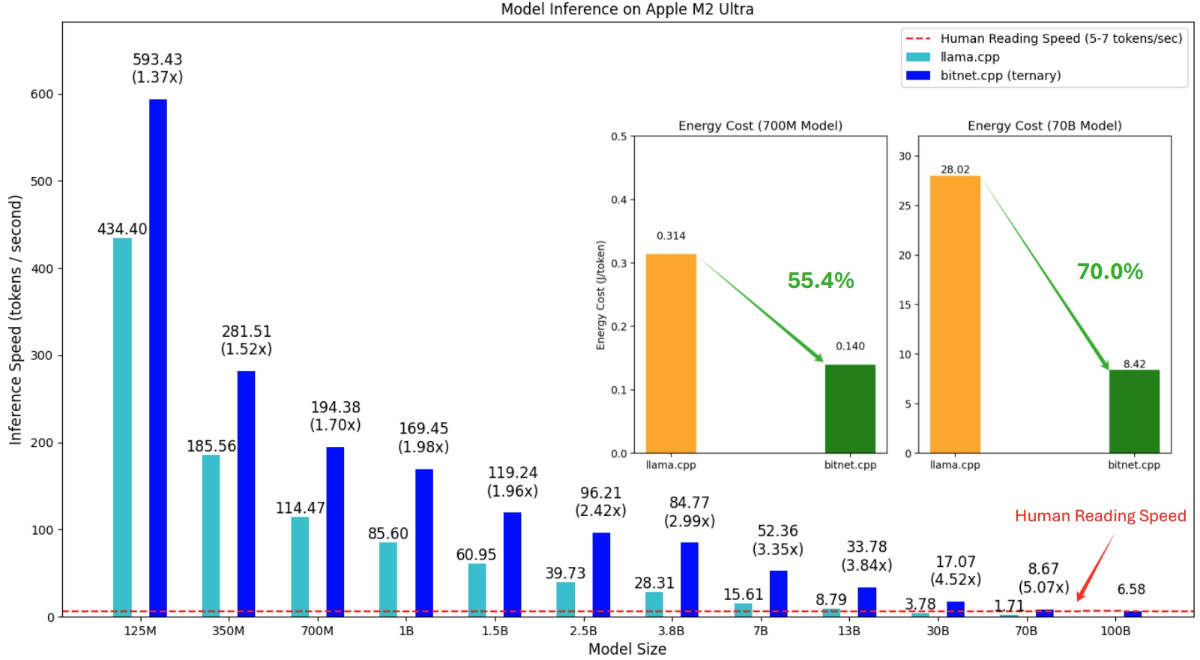
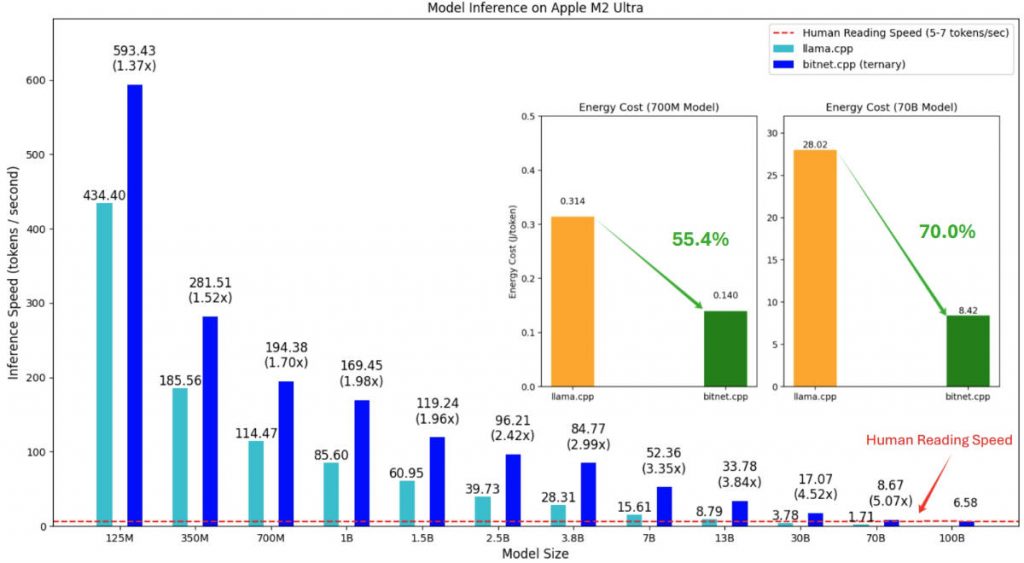
- Speed: Achieves 2.37x to 6.17x faster inference on x86 CPUs and 1.37x to 5.07x on ARM CPUs compared to conventional 16-bit implementations.
- Energy Efficiency: Cuts energy usage by 71.9%–82.2% on x86 and 55.4%–70.0% on ARM, making it ideal for battery-powered or thermally constrained devices.
- Scalability: Successfully runs a 100-billion-parameter BitNet b1.58 model on a single CPU, generating text at 5–7 tokens per second—comparable to human reading speed.
These aren’t theoretical gains. They’re measured on real hardware using official benchmarks from Microsoft, demonstrating that high-performance local LLMs are no longer a distant dream.
Ideal Use Cases: Where BitNet Shines
BitNet is especially valuable in scenarios where cloud reliance is impractical or undesirable:
- On-device AI: Deploy intelligent assistants, translators, or coding copilots directly on user devices without internet connectivity.
- Edge computing: Run LLM-powered analytics on drones, IoT gateways, or industrial controllers with limited compute resources.
- Privacy-sensitive applications: Keep user data on-device—critical for healthcare, finance, or enterprise tools where data leakage is unacceptable.
- Cost-conscious development: Avoid recurring cloud API fees by running inference locally, even on low-end hardware.
Whether you’re a startup building a privacy-first chat app or a researcher prototyping multimodal agents on a laptop, BitNet removes the biggest barriers to LLM adoption: cost, power, and hardware dependency.
Getting Started: Simple Setup, Immediate Results
Despite its advanced underpinnings, BitNet is remarkably easy to use. The workflow is designed for developer productivity:
- Install dependencies: Python ≥3.9, CMake ≥3.22, and Clang ≥18 (or Visual Studio 2022 on Windows).
- Download a pre-quantized model from Hugging Face (e.g.,
microsoft/BitNet-b1.58-2B-4T). - Build the runtime using the provided
setup_env.pyscript with your chosen quantization kernel (i2_sortl1). - Run inference with a single command:
python run_inference.py -m models/BitNet-b1.58-2B-4T/ggml-model-i2_s.gguf -p "Explain quantum computing simply." -cnv
You can also benchmark performance using the included e2e_benchmark.py script or convert your own .safetensors checkpoints to BitNet-compatible GGUF format.
The entire stack is built on llama.cpp, ensuring compatibility with existing toolchains while adding custom kernels optimized for ternary arithmetic.
Current Limitations and Practical Notes
While BitNet represents a major leap forward, it’s important to understand its current scope:
- CPU-first: The initial release focuses exclusively on CPU inference. GPU and NPU support is planned for future versions.
- Model format: Only supports 1.58-bit quantized models in GGUF format with specific quantization types (
i2_s,tl1). Not all LLMs can be converted—only those trained or adapted for ternary weights. - Research-grade models: Most available BitNet models (e.g., BitNet b1.58-3B, Llama3-8B-1.58) are released for research and demonstration purposes. They may lack the fine-tuning or safety layers of production-grade assistants.
That said, the framework is actively evolving, with new models, kernels, and hardware support added regularly—evidenced by recent releases like the official 2B-parameter model and GPU inference kernels.
Summary
BitNet redefines what’s possible for local LLM inference. By compressing models to just 1.58 bits per weight while preserving performance, it unlocks unprecedented speed and energy savings on commodity CPUs. For developers, researchers, and product teams looking to deploy LLMs offline, affordably, and sustainably, BitNet offers a compelling—and increasingly mature—solution. With open-source code, clear documentation, and strong Microsoft backing, it’s ready for real-world adoption today.