If you’ve ever tried to understand how a deep reinforcement learning (DRL) algorithm truly works—only to get lost in layers of abstract classes, hidden callbacks, or fragmented modular code—you’re not alone. Many popular DRL libraries prioritize software engineering elegance over pedagogical clarity, making it frustrating for students, researchers, and prototypers to inspect or modify core logic.
Enter CleanRL: an open-source library that rethinks DRL implementation from the ground up. Instead of sprawling modular architectures, CleanRL offers high-quality, single-file implementations of state-of-the-art algorithms—each containing every detail needed to run, train, and understand the method in a self-contained script. No hidden abstractions. No inheritance trees. Just clear, runnable code that matches what you see in papers.
Originally introduced in a Journal of Machine Learning Research (JMLR) paper, CleanRL has become a go-to resource for those who value transparency, reproducibility, and ease of debugging—without sacrificing scalability or performance.
Why CleanRL Stands Out
Self-Contained, Single-File Algorithms
Each algorithm in CleanRL lives in one file. Take ppo_atari.py: just ~340 lines of code, yet it includes everything—from environment setup and model definition to training loops, hyperparameters, and logging. This design eliminates the need to jump across dozens of files to grasp how Proximal Policy Optimization (PPO) actually works on Atari games.
For learners and researchers, this is transformative. You’re not reading an interface—you’re reading the full implementation.
Built-In Experiment Tracking & Visualization
CleanRL integrates seamlessly with TensorBoard and Weights & Biases (W&B). With a single flag (--track), you can log:
- Training metrics (e.g., returns, losses)
- Hyperparameters
- Dependencies
- Videos of agent gameplay (critical for debugging behavior)
This makes it trivial to compare runs, share results, or reproduce someone else’s experiment—down to the exact random seed.
Strong Local Reproducibility
Reproducibility in RL is notoriously hard. CleanRL tackles this head-on by:
- Explicitly seeding all randomness sources (NumPy, PyTorch, environment)
- Pinning dependency versions via
uvorpip - Avoiding non-deterministic operations where possible
This means if you run the same script twice with the same seed, you’ll get identical results—a rarity in many RL codebases.
Scalable Despite Simplicity
Don’t mistake simplicity for limitation. CleanRL has orchestrated experiments across 2,000+ cloud machines using Docker and AWS Batch. Its minimal design actually enhances debugging at scale: when something fails, you’re not hunting through layers of abstraction—you’re looking at the actual training loop.
Ideal Use Cases
CleanRL shines in two primary scenarios:
- Learning & Teaching DRL: Whether you’re a student trying to implement PPO for the first time or an instructor preparing lecture materials, CleanRL’s files serve as authoritative, readable references.
- Rapid Prototyping: Need to test a new loss function, modify an exploration strategy, or add a custom encoder? CleanRL’s flat structure lets you edit core logic directly—no subclassing, no plugin systems, no framework constraints.
It’s not designed as a production SDK or a modular library you import into large codebases. Instead, it’s a research-first toolkit optimized for understanding and iteration.
Getting Started in Minutes
CleanRL is easy to run locally:
git clone https://github.com/vwxyzjn/cleanrl.git cd cleanrl uv pip install . uv run python cleanrl/ppo.py --env-id CartPole-v0 --total-timesteps 50000
Want to track experiments in the cloud? Just add --track --wandb-project-name my-project.
CleanRL supports a wide range of environments:
- Classic control: CartPole, Pendulum
- Atari: Breakout, Pong (with optional
envpoolfor 3–4x speedup) - MuJoCo: Humanoid, Ant (continuous control)
- Procgen: StarPilot, CoinRun (generalization benchmarks)
- Multi-agent: PettingZoo integration
Each environment has its own tailored script (e.g., ppo_atari.py, sac_continuous_action.py), so you always see exactly how the algorithm adapts to the domain.
Trade-Offs to Understand
CleanRL makes deliberate design choices:
- ✅ Pros: Clarity, debuggability, reproducibility, minimal dependencies
- ❌ Cons: Code duplication across files (intentional for independence), not importable as a library
If your goal is to build a large-scale RL service with shared modules, CleanRL isn’t the right fit. But if you want to understand, modify, or verify how an algorithm works—CleanRL is purpose-built for that.
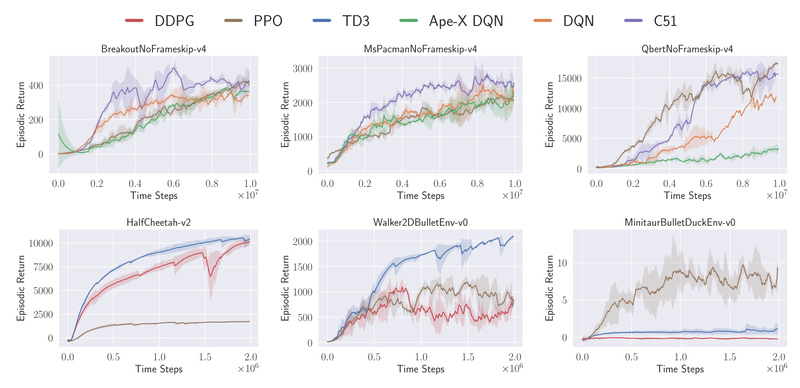
Evidence of Quality: Open Benchmarks
CleanRL doesn’t just claim correctness—it proves it. All implementations are rigorously benchmarked across 7+ algorithms and 34+ environments at https://benchmark.cleanrl.dev.
These public reports—powered by Weights & Biases—show:
- Training curves matching or exceeding baselines
- GPU utilization metrics
- Gameplay videos
- Full hyperparameter sets
This transparency lets you validate performance before committing to CleanRL in your own work.
Summary
CleanRL fills a critical gap in the deep reinforcement learning ecosystem: it bridges the divide between academic papers and working code by offering complete, readable, and reproducible implementations in a single file. Whether you’re learning DRL for the first time, prototyping a novel idea, or verifying baseline performance, CleanRL removes the friction of obscure abstractions and delivers exactly what you need—nothing more, nothing less.
With strong community support, cloud scalability, and public benchmarking, CleanRL isn’t just “clean”—it’s research-ready.