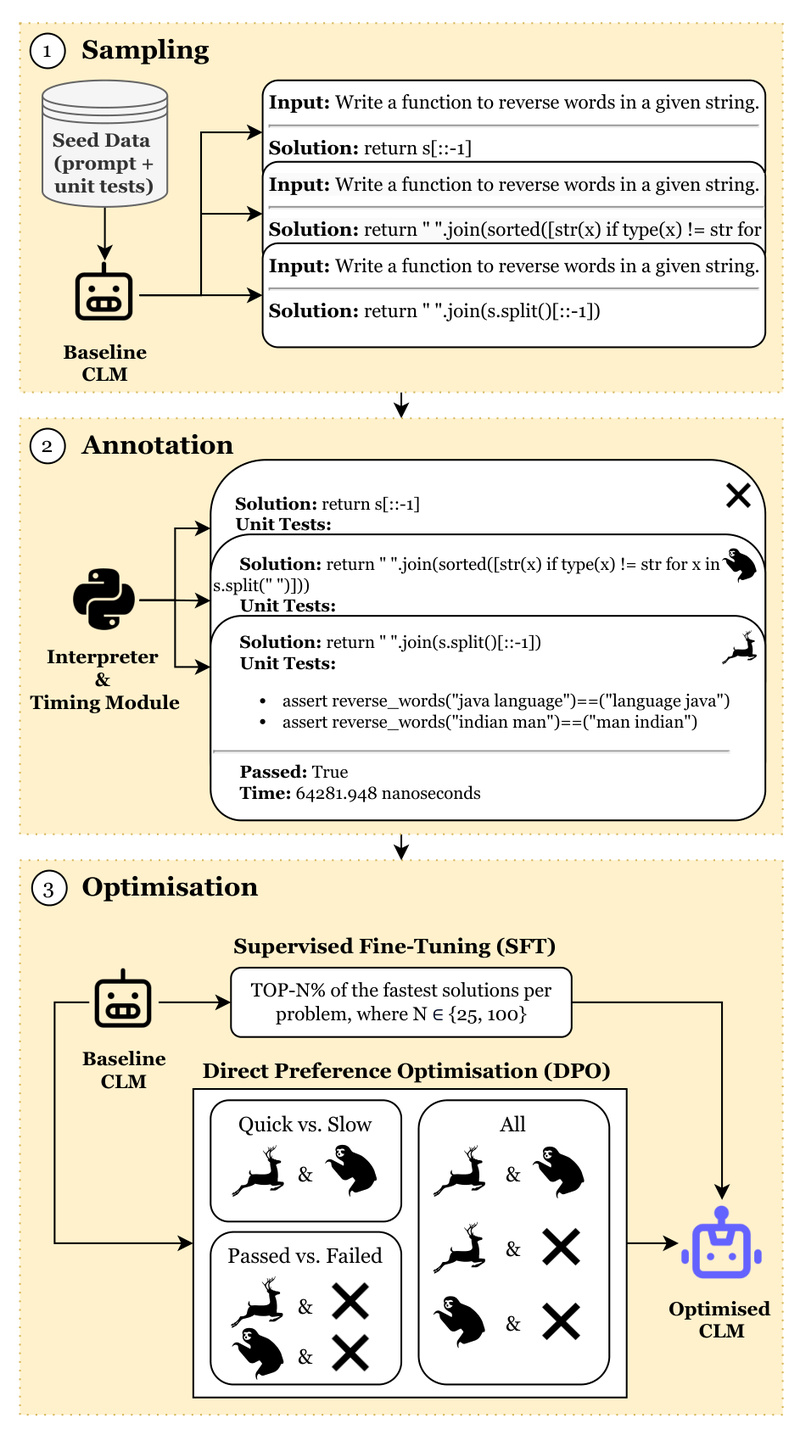
Modern code language models (CLMs) excel at generating functionally correct programs—but often at the cost of runtime efficiency. Conversely, efforts to optimize generated code for speed frequently degrade correctness, creating a frustrating trade-off for engineers, researchers, and product teams who need both. Enter Code-Optimise, a novel framework that simultaneously optimizes for functional correctness and execution speed by leveraging self-generated preference data. Unlike prior approaches that depend on large teacher models or external evaluators, Code-Optimise is lightweight, self-contained, and designed for real-world deployment.
Developed by researchers at Huawei Noah’s Ark Lab and open-sourced under the Apache license, Code-Optimise demonstrates measurable improvements: up to 6% faster execution on in-domain benchmarks, 3% on out-of-domain tasks, and a striking 48% reduction in code length on the MBPP dataset—all while improving pass@k scores. This makes it particularly valuable for applications where correctness, latency, and inference cost matter—such as coding assistants, automated code review systems, or production code generation pipelines.
Why You Can’t Ignore Runtime Efficiency in Code Generation
Most code generation benchmarks focus solely on whether a solution passes unit tests. While essential, this narrow view ignores a critical engineering reality: two functionally correct programs can differ wildly in performance. A correct but slow algorithm may be unusable in production due to latency or resource constraints. Traditional fine-tuning or distillation methods that prioritize efficiency often sacrifice correctness, leaving developers stuck choosing between “right but slow” and “fast but broken.”
Code-Optimise resolves this dilemma by treating correctness and runtime as joint optimization objectives. It does so without requiring external oracles—instead, it generates diverse code samples, evaluates them internally for both pass/fail status and execution time, and constructs preference pairs that guide model refinement. This self-sufficient loop ensures the model learns to favor solutions that are not only correct but also efficient.
Core Innovations That Set Code-Optimise Apart
Self-Generated Preference Data with Dual Signals
Code-Optimise doesn’t rely on human annotations or larger teacher models. Instead, it automatically labels its own generations using two binary signals:
- Correctness: Does the code pass the test suite? (Yes/No)
- Runtime: Is execution faster or slower than a threshold? (Fast/Slow)
These signals combine to form preference pairs—for example, preferring a correct and fast solution over a correct but slow one. This dual-signal approach enables nuanced learning that pure correctness-based training misses.
Lightweight and Model-Agnostic Design
The framework works with existing open-source code models like StarCoder-1B and supports both Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO). There’s no dependency on proprietary APIs or massive ensembles, making it accessible for teams with limited compute or privacy constraints.
Dynamic Solution Selection to Prevent Overfitting
Rather than using all generated samples, Code-Optimise employs a dynamic filtering strategy—selecting only the top-p working solutions during SFT or constructing balanced preference pairs for DPO. This reduces overfitting to noisy or redundant generations and improves generalization.
Shorter Code, Lower Inference Costs
As a valuable side effect, optimized models produce significantly more concise code. On MBPP, average program length drops by 48%; on HumanEval, by 23%. Shorter outputs mean faster token generation, reduced API costs, and easier human review—critical for scalable developer tooling.
Practical Use Cases Where Code-Optimise Delivers Value
- Production Code Generation: Deploy models that output correct and performant code for backend services, data pipelines, or embedded systems.
- Intelligent IDEs and Copilots: Enhance coding assistants to suggest solutions that are not just syntactically valid but also resource-efficient.
- Competitive Programming & Benchmarking: Improve submissions on platforms like Codeforces or LeetCode where time limits are strict.
- Automated Code Refactoring: Use the framework to iteratively refine legacy or auto-generated code for better performance without breaking functionality.
Getting Started: A Step-by-Step Workflow
Code-Optimise provides a clear, script-driven pipeline that integrates smoothly into existing workflows:
1. Sample Diverse Code Solutions
Use sample.sh to generate multiple candidate programs per problem:
--regen True --data_path mbpp --model_path StarCoder-1B --n_seq 100 --temp 0.6
Higher n_seq and moderate temp encourage diversity, which is crucial for building rich preference data.
2. Annotate for Correctness and Runtime
Run the same script with --regen False to execute all samples and record:
- Pass/fail status against test cases
- Execution time (in a controlled environment)
Critical note: For reliable timing, run evaluations on a dedicated machine with no background processes and avoid monitoring tools like
htopduring measurement.
3. Merge and Filter Annotations
The merge.sh script consolidates results and filters out invalid or outlier runs, producing clean synthetic datasets ready for training.
4. Optimize via SFT or DPO
Choose your training strategy:
- SFT: Retrain the model on the top-p correct and fast solutions (
--optim sft --top_p 25) - DPO: Train using preference pairs (e.g., “quick vs. slow” with
--task qvs)
Both approaches support --augment True to enable dynamic selection and improve robustness.
5. Evaluate on MBPP or HumanEval
Use eval.sh to generate and annotate test-time samples, then compare pass rates and runtimes against baselines.
Limitations and Best Practices
While powerful, Code-Optimise has practical boundaries:
- Environment sensitivity: Runtime measurements must be consistent—varying hardware or system load invalidates comparisons.
- Dataset scope: Validated on MBPP and HumanEval; performance on domain-specific code (e.g., SQL, CUDA, or embedded C) requires empirical verification.
- Timing discipline: Background processes can skew results, so isolate evaluation runs.
These constraints are manageable with careful experimental design and reflect the inherent challenge of measuring code efficiency—not a flaw in the framework itself.
Summary
Code-Optimise breaks the false dichotomy between correctness and efficiency in code generation. By using self-generated preference data that encodes both functional accuracy and execution speed, it enables models to learn what real-world developers truly need: code that works and works fast. Its lightweight, open-source implementation, compatibility with popular code models, and demonstrated gains in runtime, correctness, and code conciseness make it a compelling choice for anyone building or deploying code-generation systems. Whether you’re enhancing a coding assistant, optimizing an automated pipeline, or researching next-generation CLMs, Code-Optimise offers a practical, proven path forward—without forcing you to sacrifice one goal for the other.