If you’re building or maintaining AI-powered coding assistants, you’ve likely faced a frustrating trade-off: fine-tune a model for one specific…
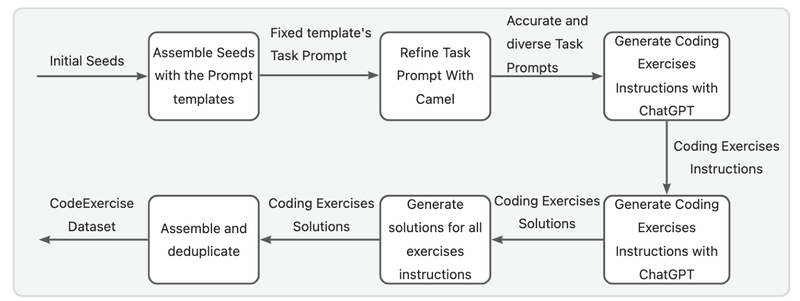
If you’re building or maintaining AI-powered coding assistants, you’ve likely faced a frustrating trade-off: fine-tune a model for one specific…
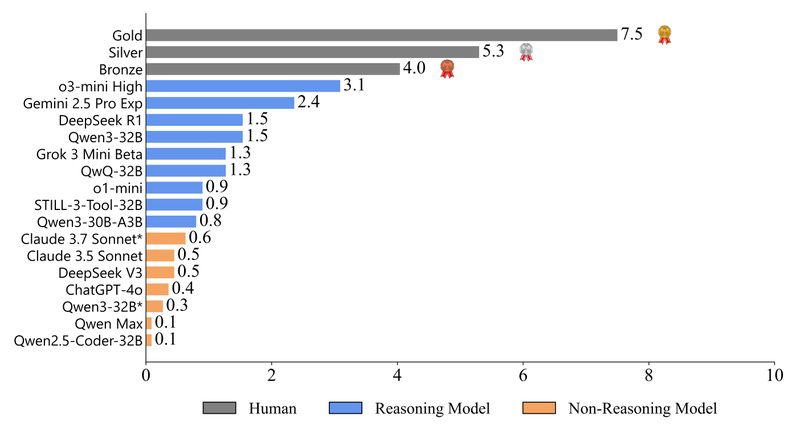
Evaluating the true reasoning capabilities of large language models (LLMs) in coding has long been hampered by benchmarks that are…
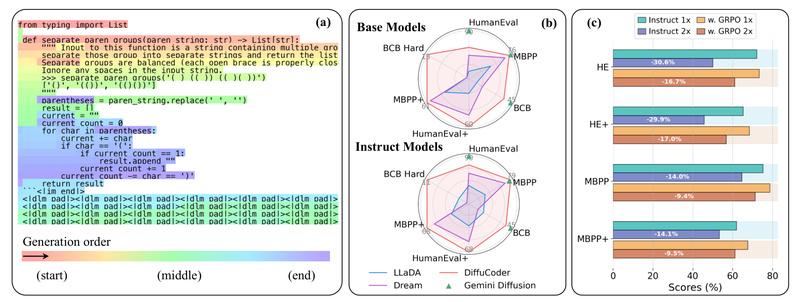
If you’re evaluating next-generation code generation tools, you’ve likely worked with autoregressive (AR) large language models—systems that build code one…
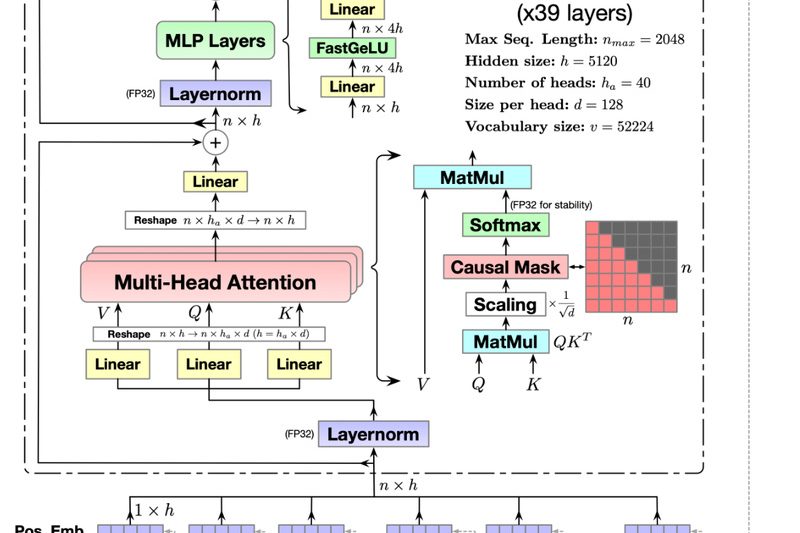
For software teams working across multiple programming languages—or developers tired of vendor lock-in with proprietary AI coding tools—CodeGeeX offers a…
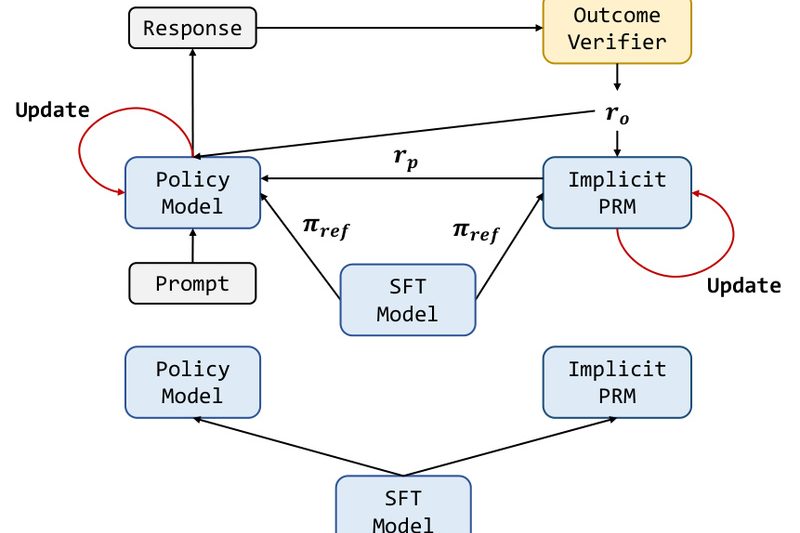
If you’re working to improve large language models (LLMs) on hard reasoning tasks—like math problem solving or competitive programming—you’ve likely…
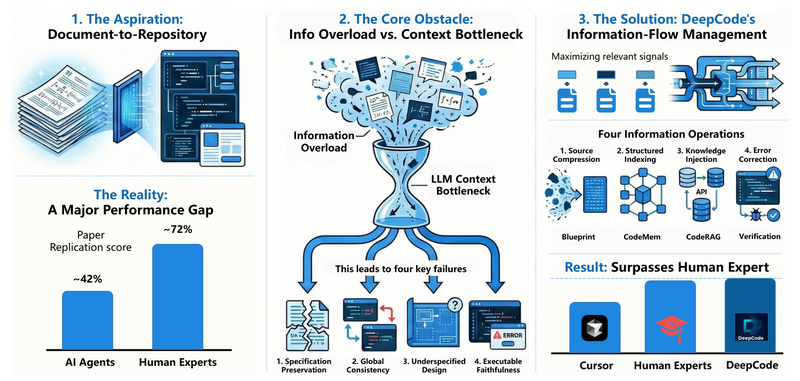
Imagine being able to feed a research paper, a technical specification, or even a rough product description into a system—and…
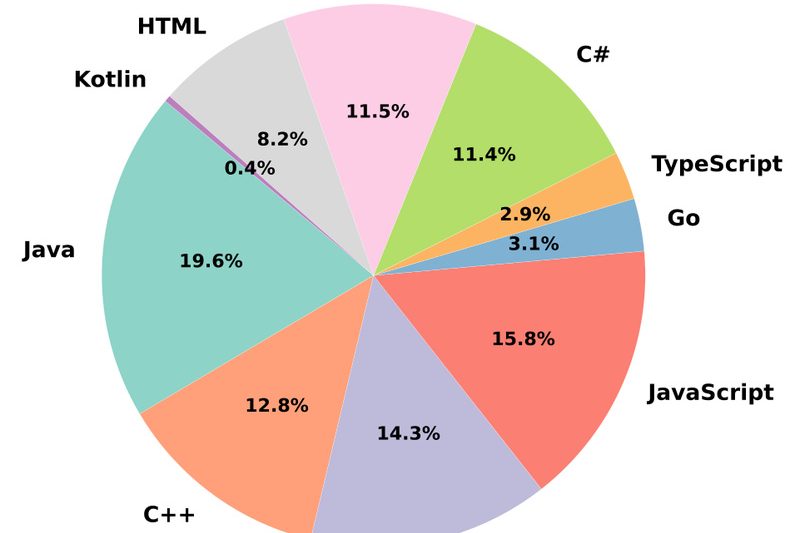
aiXcoder-7B is a 7-billion-parameter open-source large language model (LLM) purpose-built for code processing. Unlike larger models that trade inference speed…
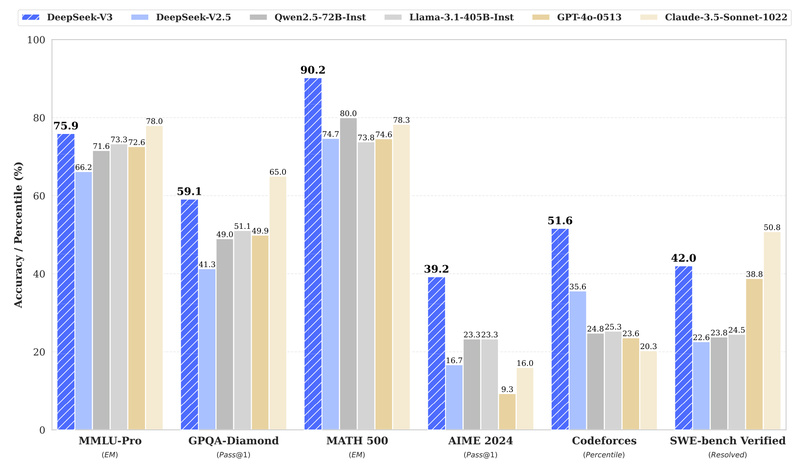
For technical decision-makers evaluating large language models (LLMs) for real-world applications, balancing raw capability, inference cost, training efficiency, and deployment…
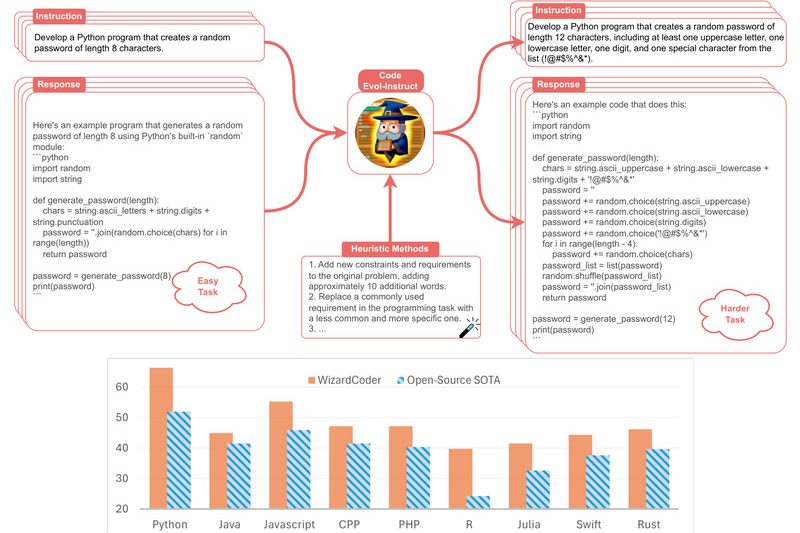
WizardCoder is a state-of-the-art open-source Code Large Language Model (Code LLM) that delivers exceptional performance on code generation tasks—often surpassing…
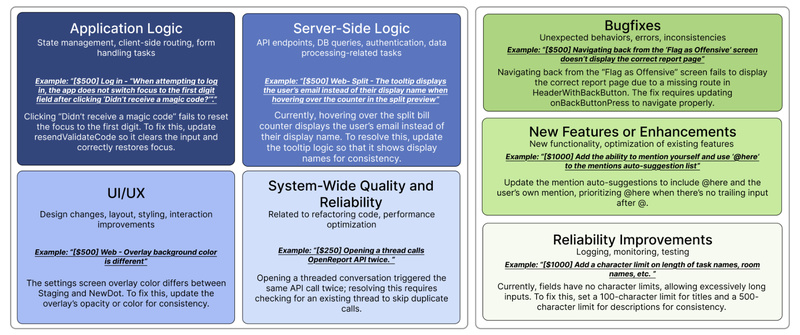
Evaluating large language models (LLMs) on synthetic coding benchmarks often fails to reflect their real-world utility. Enter SWE-Lancer—a rigorously constructed…