Evaluating how well large language models (LLMs) retrieve critical facts and perform reasoning over long documents remains a major challenge…
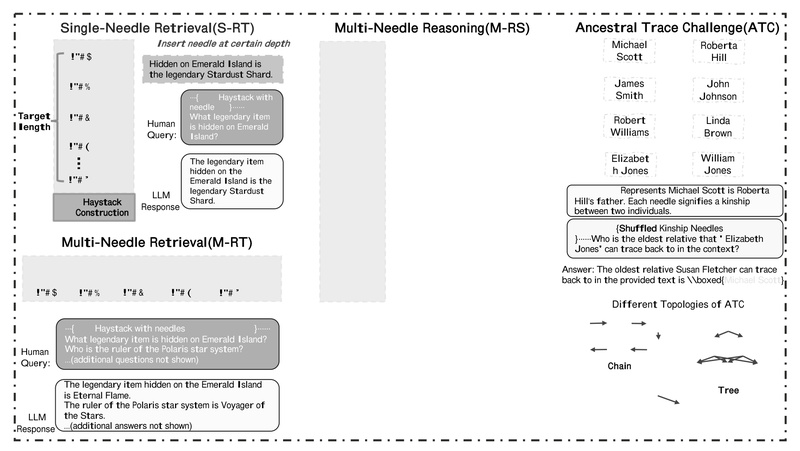
Evaluating how well large language models (LLMs) retrieve critical facts and perform reasoning over long documents remains a major challenge…
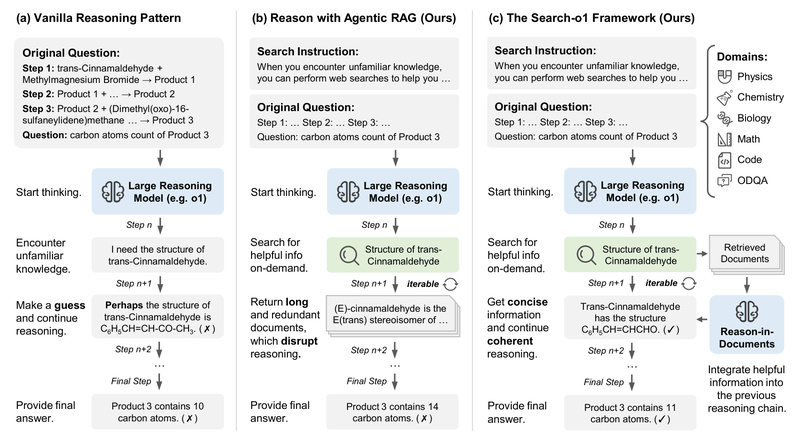
Large reasoning models (LRMs)—such as OpenAI’s o1—excel at multi-step logical reasoning, especially in science, math, and code-related tasks. But they…