Document layout analysis (DLA) is a foundational task in building real-world document understanding systems—whether you’re extracting structured data from invoices,…
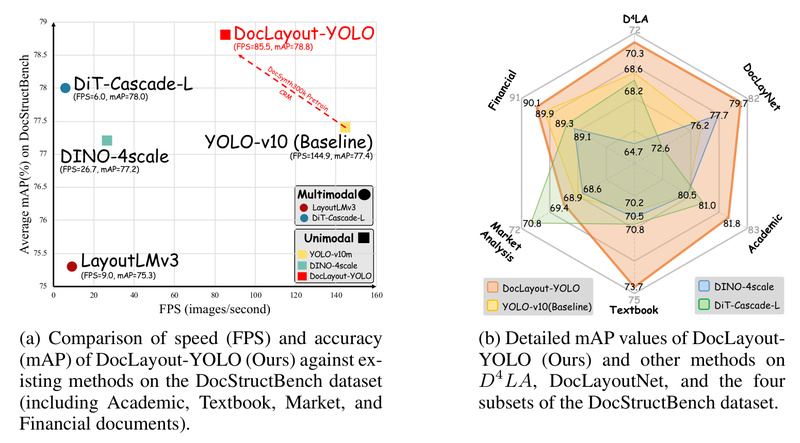
Document layout analysis (DLA) is a foundational task in building real-world document understanding systems—whether you’re extracting structured data from invoices,…

In today’s AI landscape, multimodal systems that understand both images and language are no longer a luxury—they’re a necessity. Yet,…
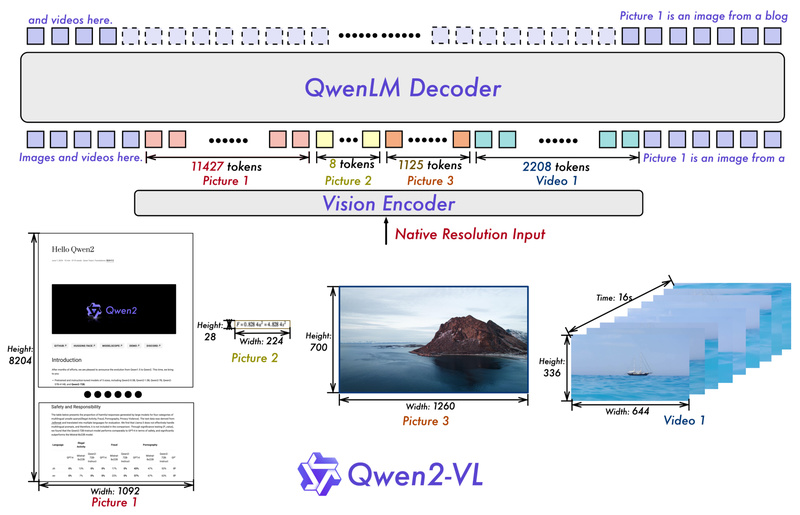
Vision-language models (VLMs) are increasingly essential for tasks that require joint understanding of images, videos, and text—ranging from document parsing…

When it comes to deploying multimodal large language models (MLLMs) in real-world applications—especially on cost-sensitive or edge devices—lightweight models are…
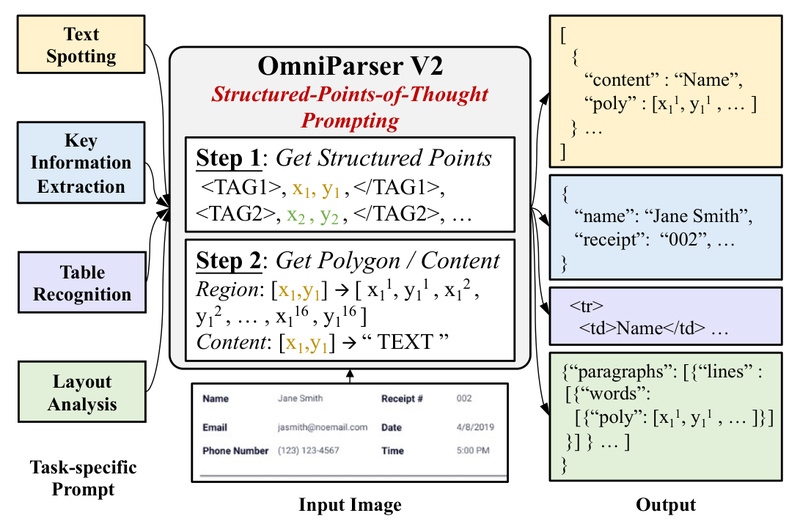
In today’s data-driven world, businesses and researchers routinely process documents—scanned invoices, forms, tables, and receipts—to extract structured information. Traditionally, this…
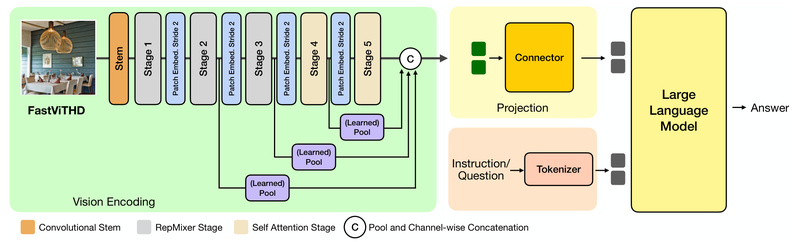
Vision Language Models (VLMs) are increasingly central to real-world applications—from mobile assistants that read documents to AI systems that interpret…
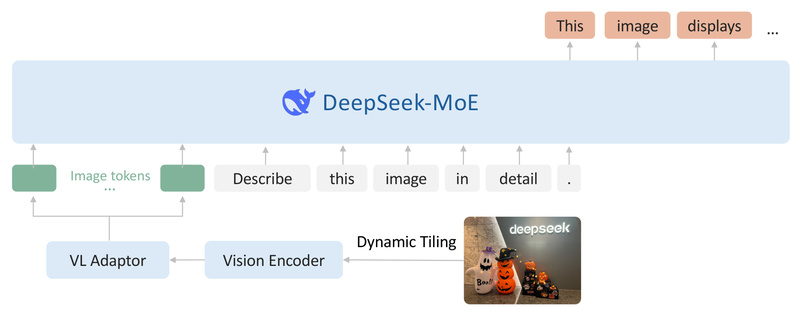
DeepSeek-VL2 is an open-source, advanced vision-language model (VLM) built on a Mixture-of-Experts (MoE) architecture, engineered for robust multimodal understanding across…