Remote sensing imagery—captured from satellites, drones, or aircraft—presents unique challenges for computer vision systems. Objects are often small, densely packed,…
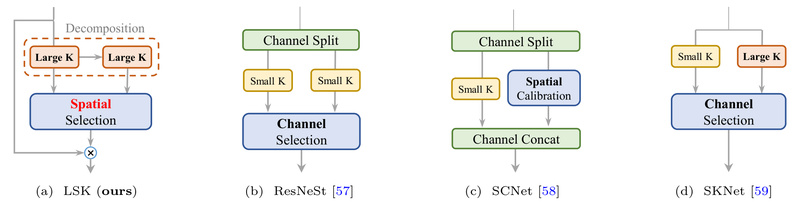
Remote sensing imagery—captured from satellites, drones, or aircraft—presents unique challenges for computer vision systems. Objects are often small, densely packed,…

PytorchInsight is a practical, research-oriented PyTorch library designed to accelerate deep learning development—especially for computer vision practitioners who need reliable,…
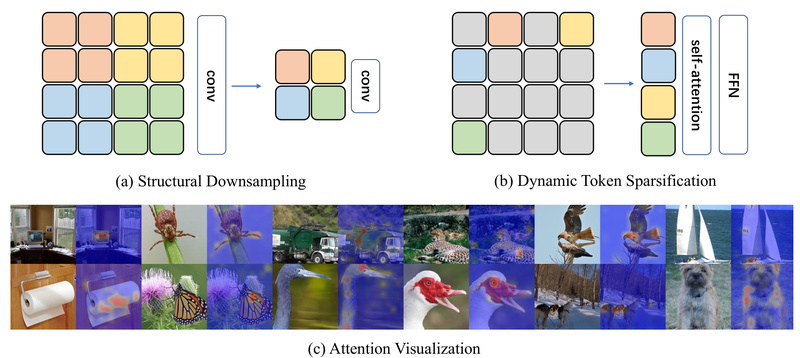
Vision Transformers (ViTs) have revolutionized computer vision, but their computational demands remain a major barrier for real-world deployment—especially on edge…
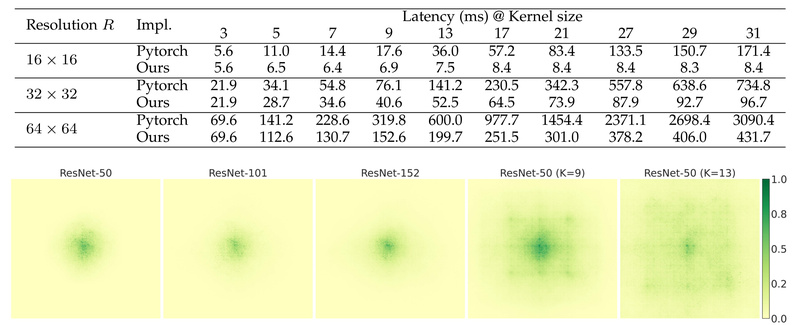
In the era of Vision Transformers and increasingly complex multimodal architectures, convolutional neural networks (ConvNets) have often been written off…
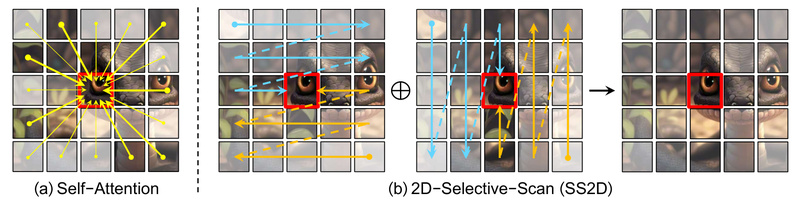
In the rapidly evolving landscape of computer vision, model efficiency and scalability are no longer optional—they’re essential. Enter VMamba, a…
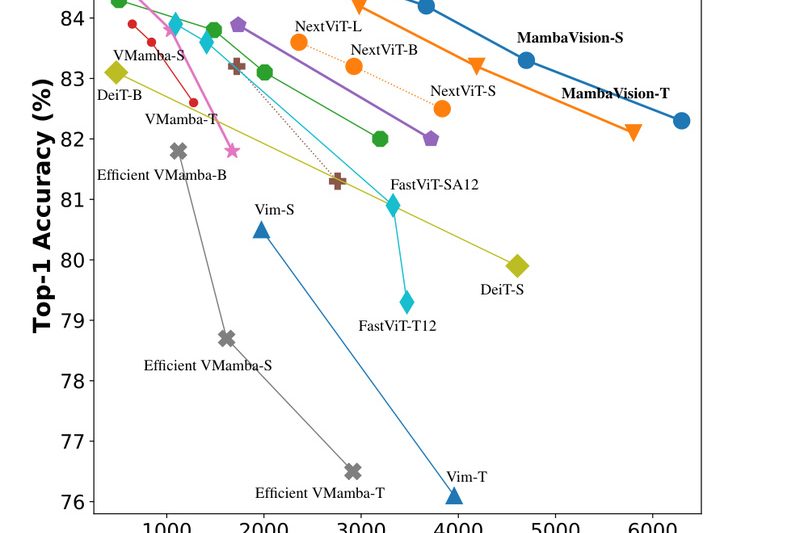
If you’re building computer vision systems that demand both high accuracy and real-world efficiency—without getting bogged down in architectural complexity—MambaVision…
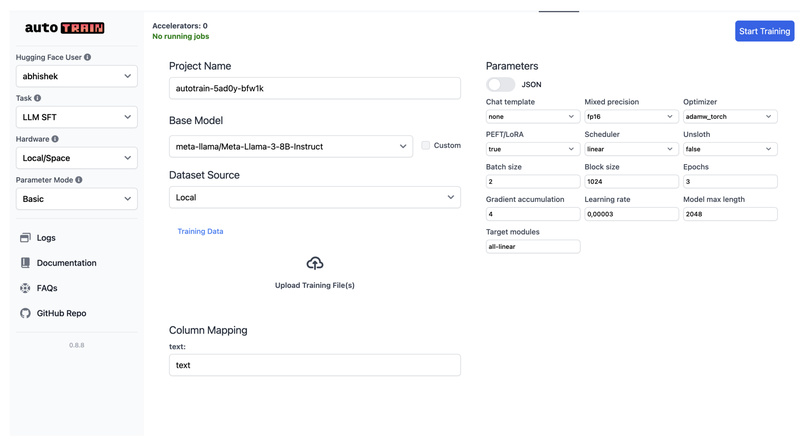
In today’s fast-moving AI landscape, fine-tuning state-of-the-art models on custom data is no longer a luxury—it’s a necessity for building…
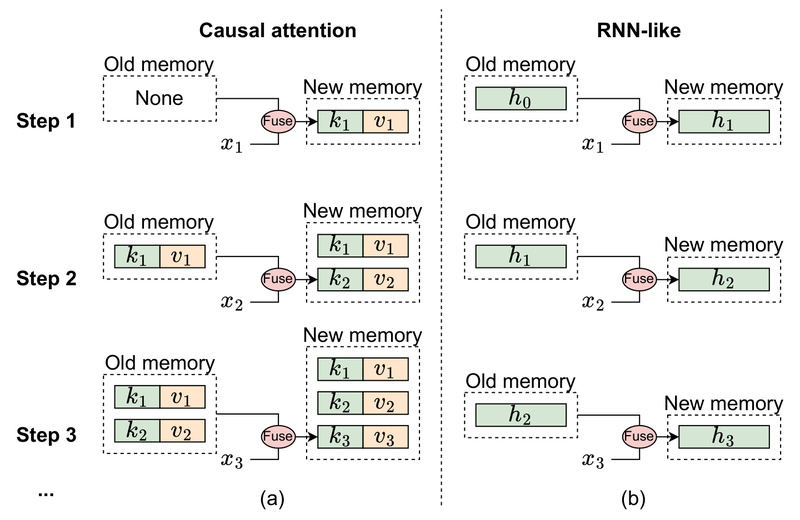
The vision community has recently seen a surge in adopting sequence modeling architectures—especially Mamba—for image tasks. Inspired by its linear…
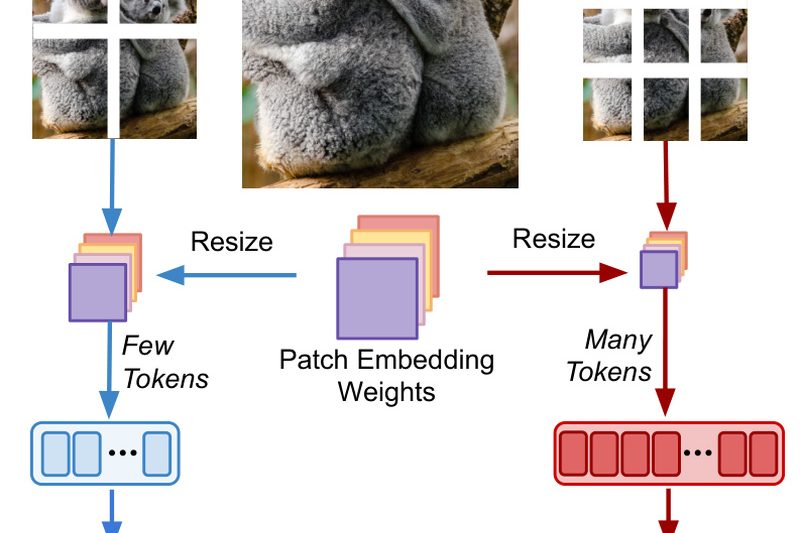
Vision Transformers (ViTs) have become a cornerstone of modern computer vision, offering strong performance across a wide range of tasks.…
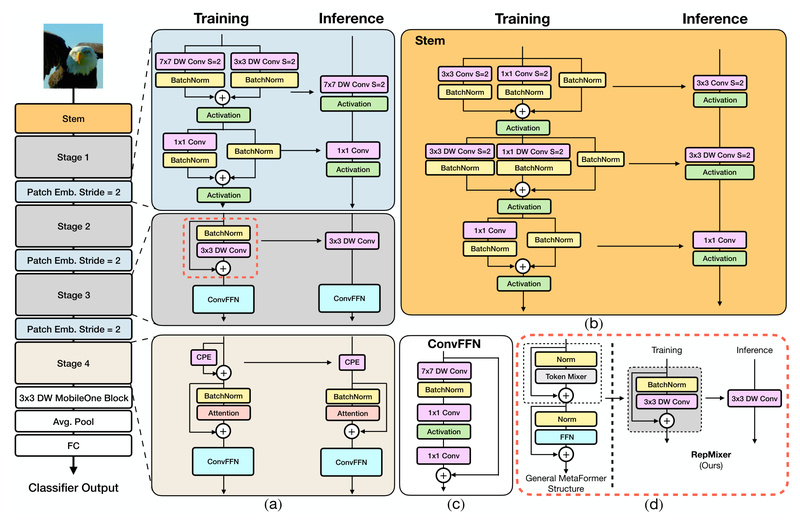
FastViT is a high-performance hybrid vision transformer designed to deliver exceptional speed and accuracy—especially on resource-constrained platforms like mobile phones…