Imagine managing a project that needs to understand speech, analyze images, interpret video frames, and respond to written prompts—all within…
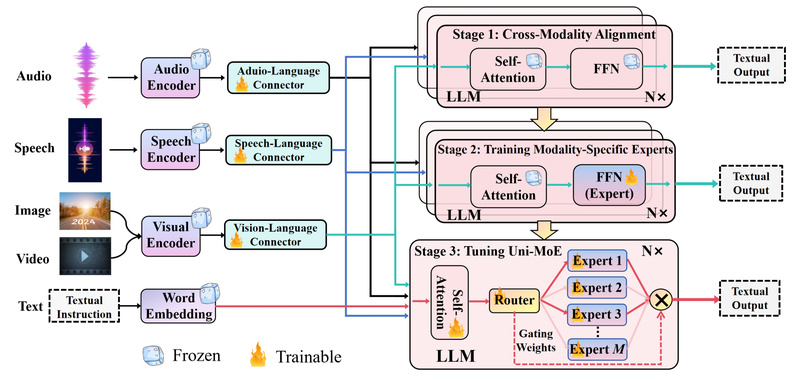
Imagine managing a project that needs to understand speech, analyze images, interpret video frames, and respond to written prompts—all within…
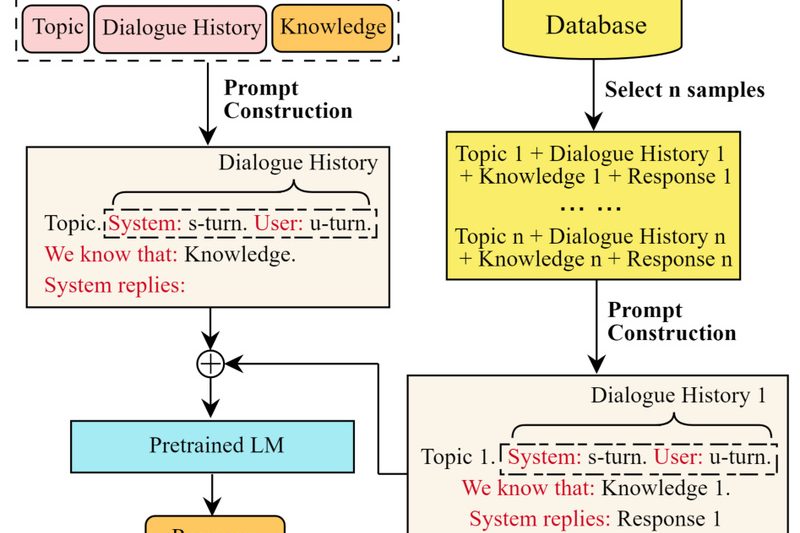
If you’re building or scaling large language models (LLMs) and have access to NVIDIA GPU clusters, Megatron-LM—developed by NVIDIA—is one…
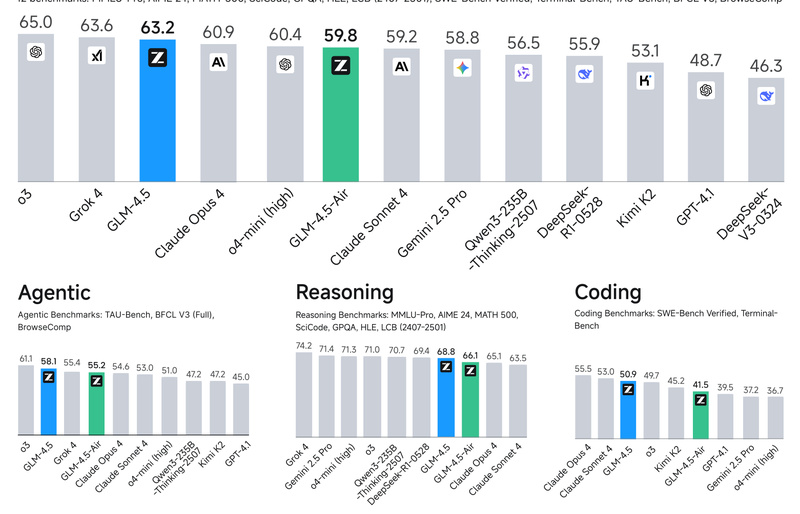
GLM-4.5 is an open-source, high-performance Mixture-of-Experts (MoE) large language model engineered specifically for intelligent agents that need to reason, code,…