What if a single large language model (LLM) could both understand and generate high-quality images—without relying on external vision encoders…
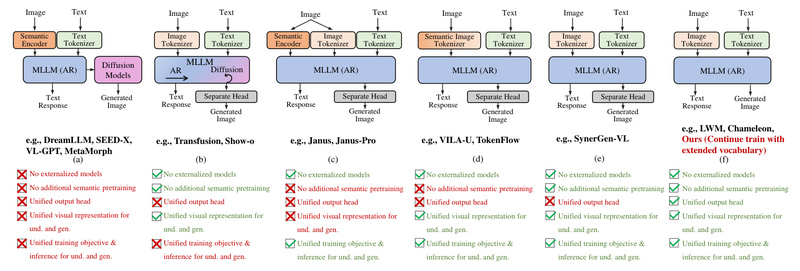
What if a single large language model (LLM) could both understand and generate high-quality images—without relying on external vision encoders…
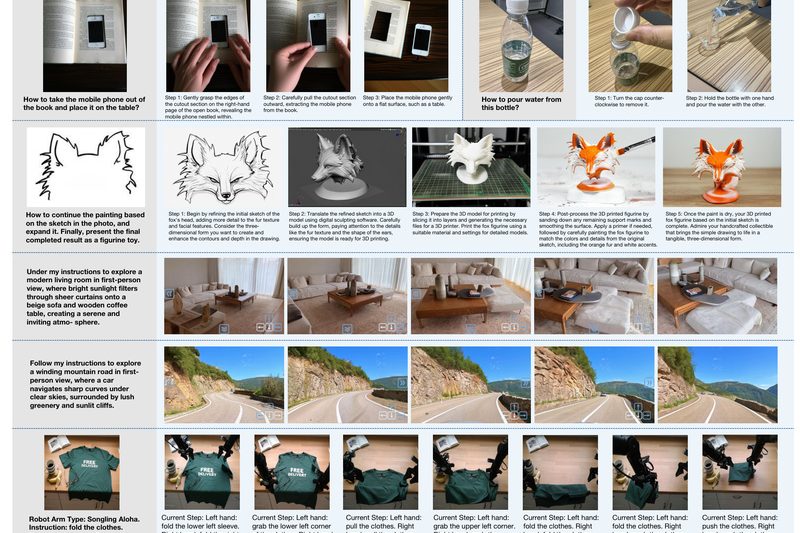
Imagine a single AI model that doesn’t just “see” or “read”—but seamlessly blends images and text in both input and…

Attention mechanisms lie at the heart of modern large language models (LLMs) and multimodal architectures—but their quadratic computational complexity remains…