Autonomous driving research has long been bottlenecked by the need for massive datasets, expensive compute infrastructure, and proprietary end-to-end frameworks.…
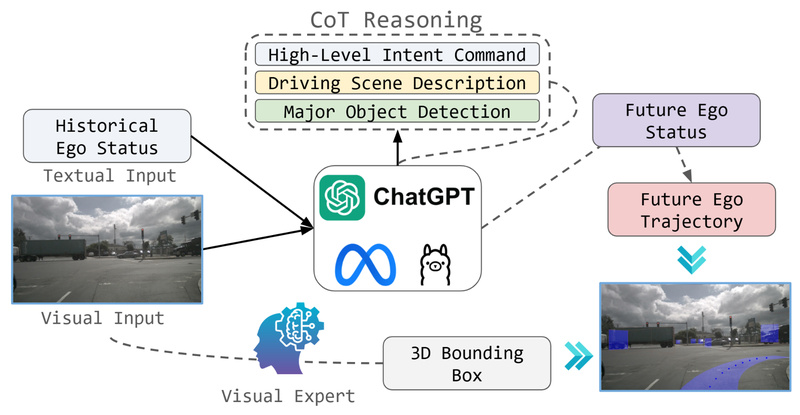
Autonomous driving research has long been bottlenecked by the need for massive datasets, expensive compute infrastructure, and proprietary end-to-end frameworks.…
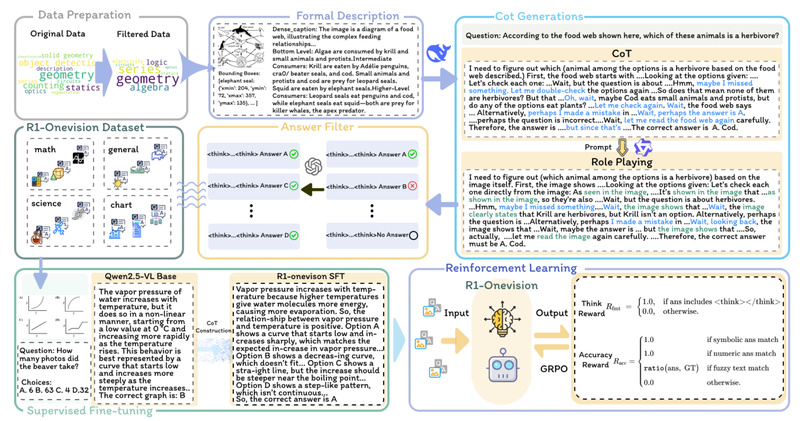
In today’s AI landscape, most multimodal models can describe what’s in an image—but few can reason through it. If your…

As Large Vision-Language Models (LVLMs) grow increasingly capable—and increasingly complex—evaluating their multimodal reasoning, perception, and reliability has become a significant…
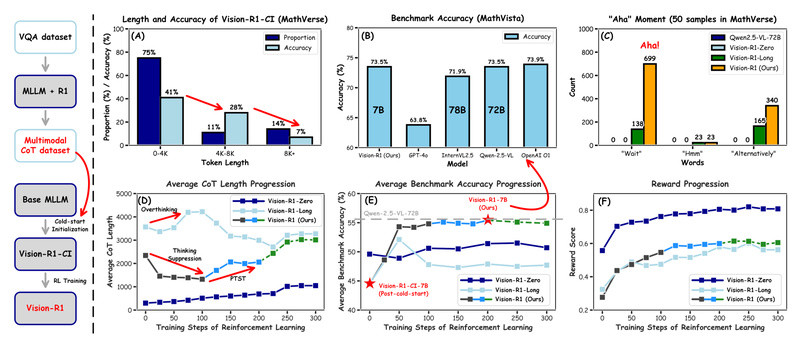
If you’re evaluating multimodal AI systems for tasks that demand deep reasoning—such as solving visual math problems, interpreting charts, or…

In the rapidly evolving field of multimodal AI, most models still struggle to combine visual understanding with precise, step-by-step logical…

In today’s AI landscape, multimodal systems that understand both images and language are no longer a luxury—they’re a necessity. Yet,…

In the rapidly evolving landscape of multimodal artificial intelligence, developers and technical decision-makers need models that go beyond basic image…
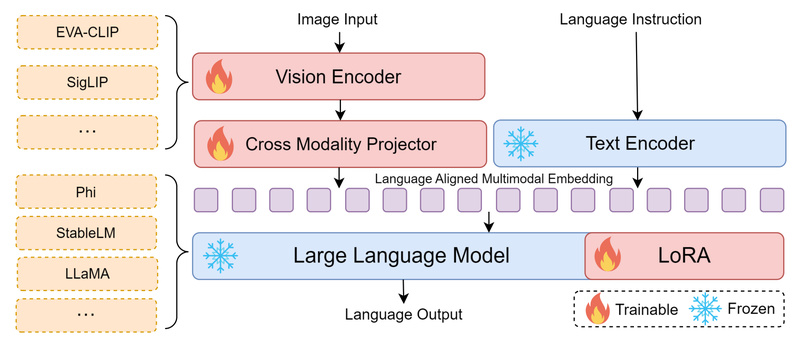
Multimodal Large Language Models (MLLMs) are transforming how machines understand and reason about visual content. Yet, their adoption remains out…

Text-to-image generation has made remarkable strides, yet even state-of-the-art models like DALL·E 3 or Stable Diffusion XL (SDXL) often stumble…
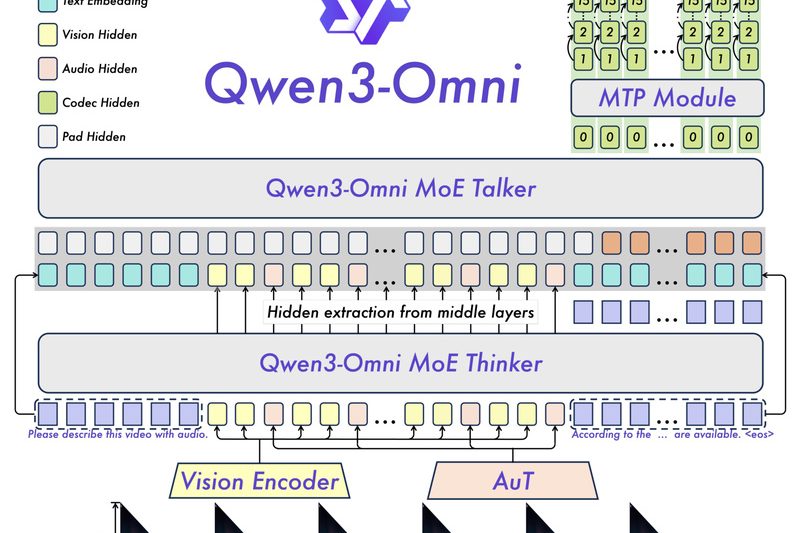
Imagine a single AI model that natively understands and generates responses across text, images, audio, and video—all in real time,…