For teams building real-world AI applications that combine vision and language—whether it’s parsing scanned documents, analyzing instructional videos, or creating…
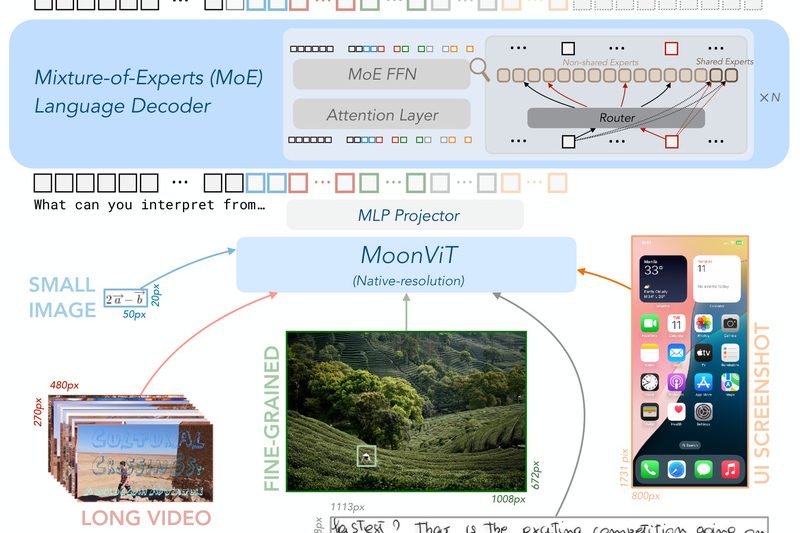
For teams building real-world AI applications that combine vision and language—whether it’s parsing scanned documents, analyzing instructional videos, or creating…
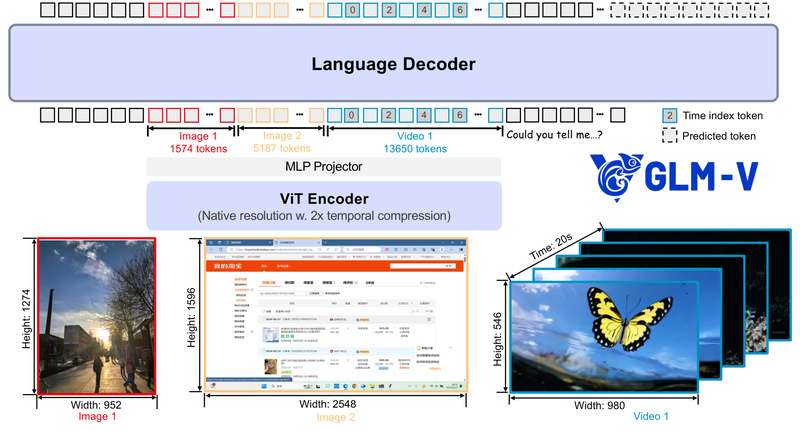
If your team is building AI applications that need to see, reason, and act—like desktop assistants that interpret screenshots, UI…

HunyuanImage-3.0 is a groundbreaking open-source image generation model developed by Tencent. Unlike traditional diffusion-based approaches, it builds a native multimodal…
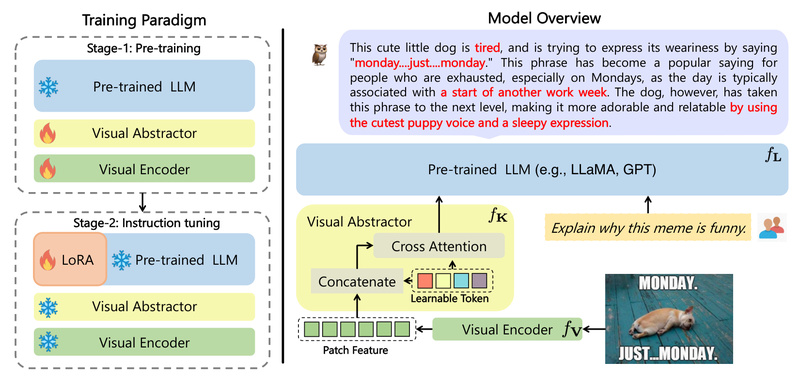
In today’s AI-driven product landscape, the ability to understand both images and text isn’t just a research novelty—it’s a practical…
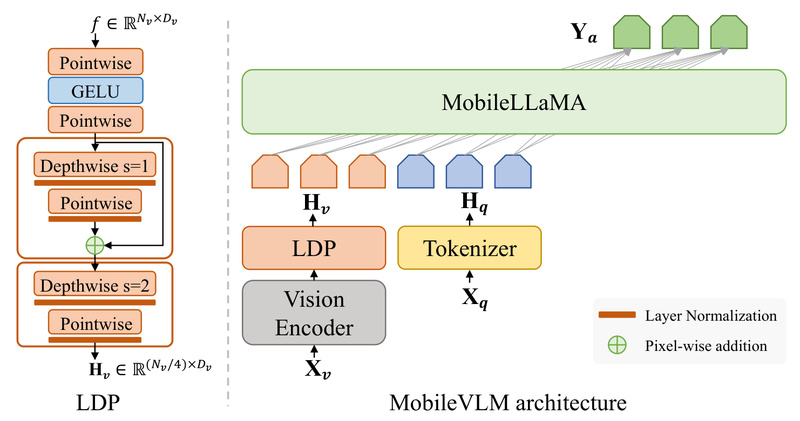
MobileVLM is a purpose-built vision-language model (VLM) engineered from the ground up for on-device deployment on smartphones and edge hardware.…
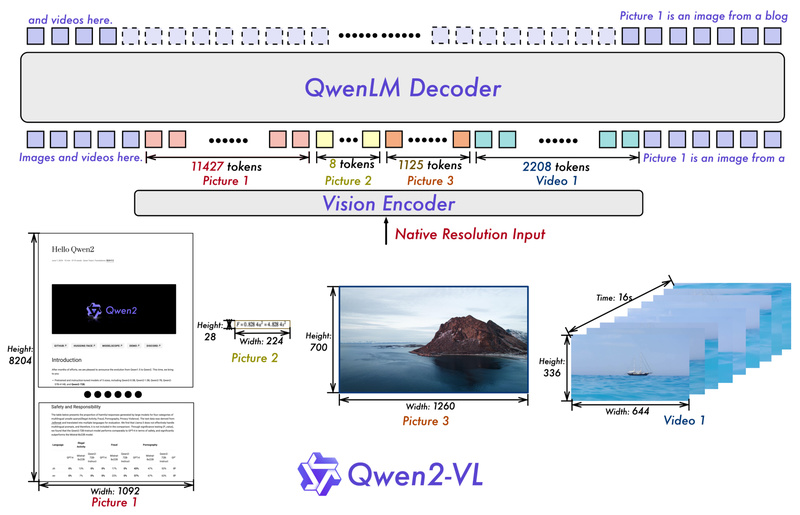
Vision-language models (VLMs) are increasingly essential for tasks that require joint understanding of images, videos, and text—ranging from document parsing…

Imagine asking a computer vision system to “segment the object that makes the woman stand higher” or “show me the…
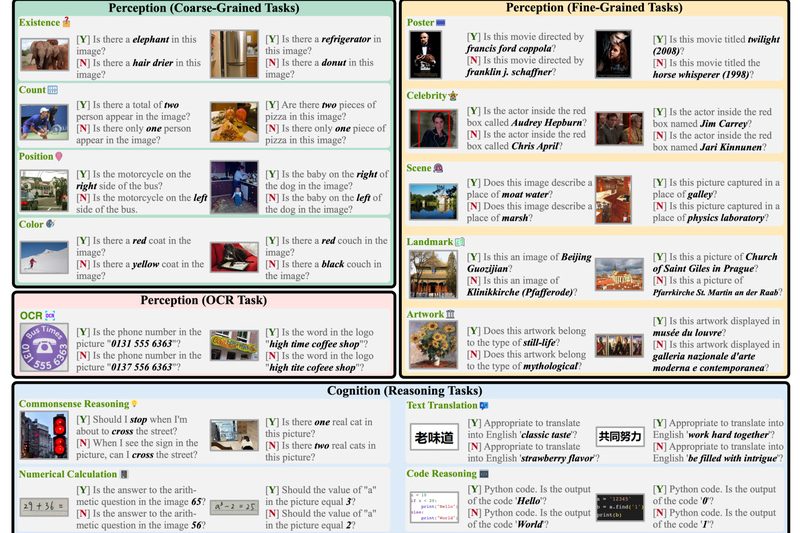
Multimodal Large Language Models (MLLMs) have captured the imagination of researchers and developers alike—promising capabilities like generating poetry from images,…
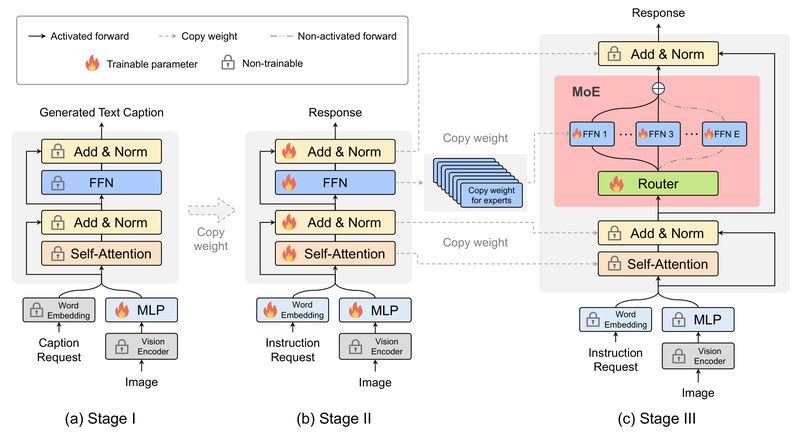
MoE-LLaVA (Mixture of Experts for Large Vision-Language Models) redefines efficiency in multimodal AI by delivering performance that rivals much larger…

Most vision-language models (VLMs) today can describe what’s in an image—but they often falter when asked to reason about it.…