Video understanding has long been a bottleneck for multimodal large language models (MLLMs). While models can recognize objects or scenes…
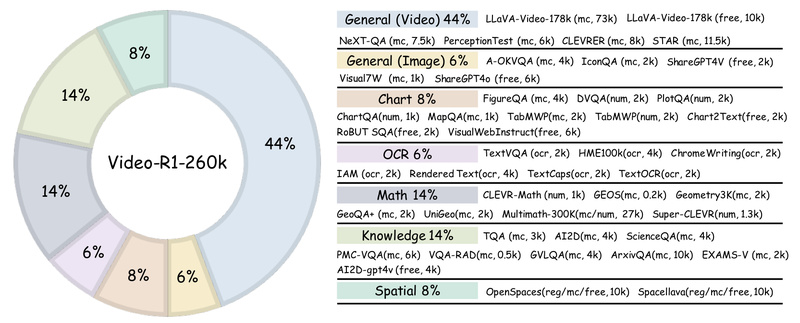
Video understanding has long been a bottleneck for multimodal large language models (MLLMs). While models can recognize objects or scenes…

Most modern Vision-Language Models (VLMs) treat images as static inputs—processed once, then reasoned about using purely text-based logic. But humans…
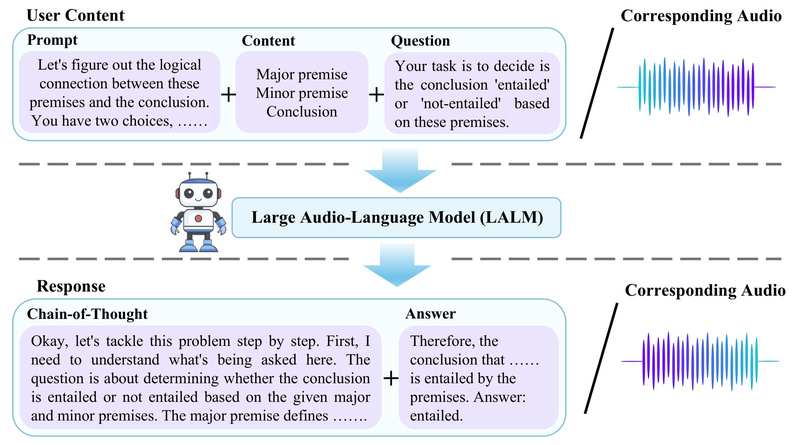
Most large language models (LLMs) today excel at reasoning over text—but what happens when the input includes sounds? Can an…