Perception Encoder (PE) redefines what’s possible with a single vision encoder. Unlike legacy approaches that demand different pretraining strategies for…
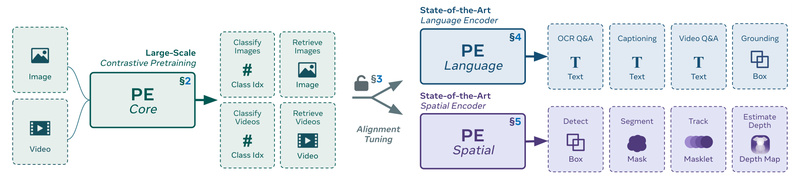
Perception Encoder (PE) redefines what’s possible with a single vision encoder. Unlike legacy approaches that demand different pretraining strategies for…