Traditional language model (LM) development follows a two-stage process: unsupervised pre-training on massive raw text corpora, followed by instruction tuning…
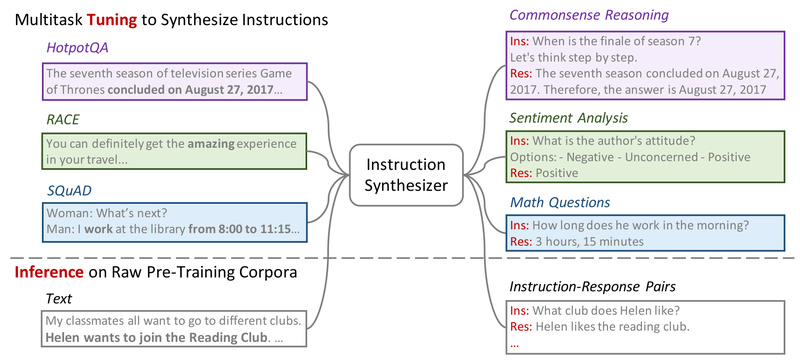
Traditional language model (LM) development follows a two-stage process: unsupervised pre-training on massive raw text corpora, followed by instruction tuning…