Vision Language Models (VLMs) are increasingly central to real-world applications—from mobile assistants that read documents to AI systems that interpret…
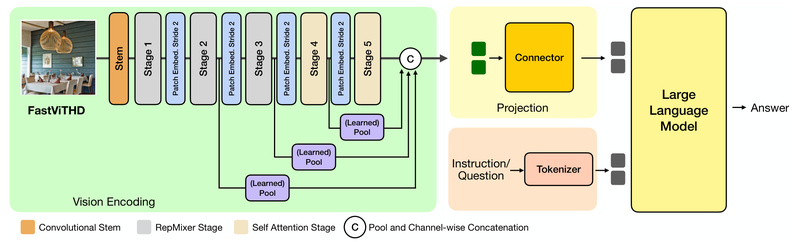
Vision Language Models (VLMs) are increasingly central to real-world applications—from mobile assistants that read documents to AI systems that interpret…