Large language models (LLMs) have demonstrated impressive capabilities in code generation and narrow reasoning tasks like mathematics. Yet, when it…
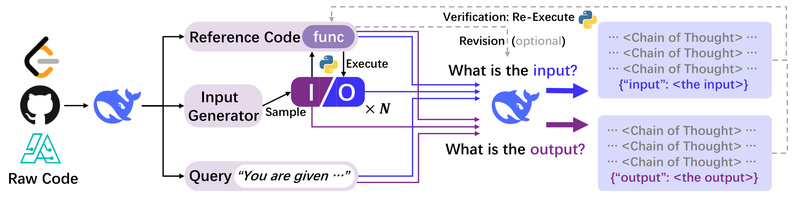
Large language models (LLMs) have demonstrated impressive capabilities in code generation and narrow reasoning tasks like mathematics. Yet, when it…

Solving complex reasoning problems is a persistent challenge for Large Language Models (LLMs). While techniques like Chain-of-Thought (CoT) prompting have…