Sa2VA represents a significant leap forward in multimodal AI by seamlessly integrating the strengths of SAM2—Meta’s state-of-the-art video object segmentation…
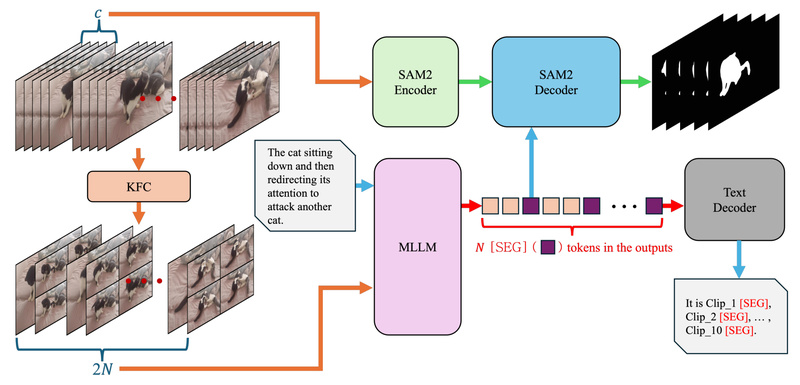
Sa2VA represents a significant leap forward in multimodal AI by seamlessly integrating the strengths of SAM2—Meta’s state-of-the-art video object segmentation…