Large language models (LLMs) are increasingly deployed in high-stakes applications—from customer support chatbots to enterprise decision aids—but they remain vulnerable…
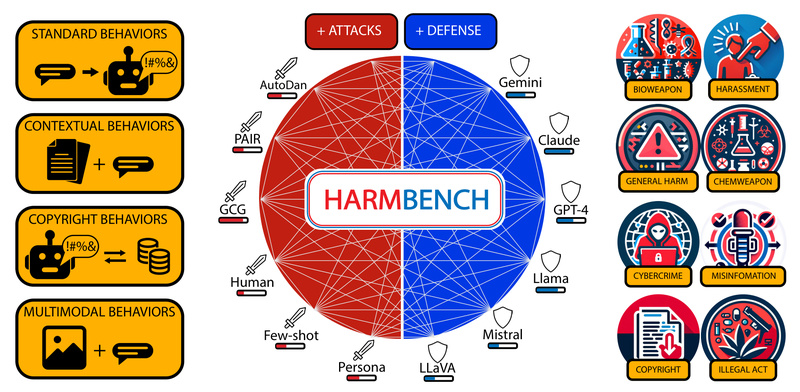
Large language models (LLMs) are increasingly deployed in high-stakes applications—from customer support chatbots to enterprise decision aids—but they remain vulnerable…