Remote sensing imagery—captured from satellites, drones, or aircraft—presents unique challenges for computer vision systems. Objects are often small, densely packed,…
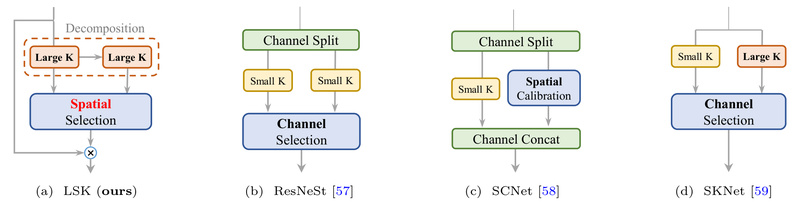
Remote sensing imagery—captured from satellites, drones, or aircraft—presents unique challenges for computer vision systems. Objects are often small, densely packed,…
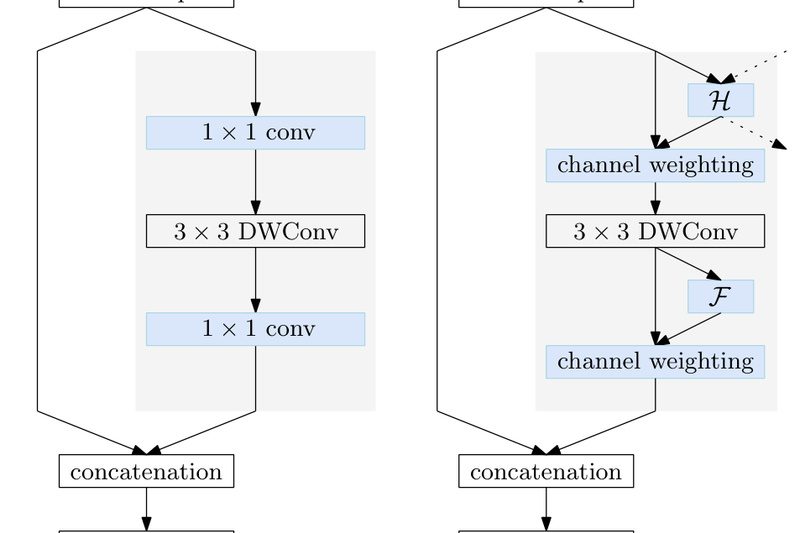
When building real-time vision applications for mobile, embedded, or edge devices, developers often face a tough trade-off: accuracy versus efficiency.…
If you’re building computer vision systems that rely on pixel-perfect understanding—like autonomous driving, medical imaging analysis, or retail scene parsing—you’ve…
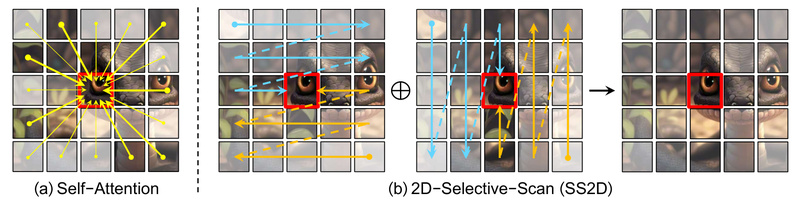
In the rapidly evolving landscape of computer vision, model efficiency and scalability are no longer optional—they’re essential. Enter VMamba, a…
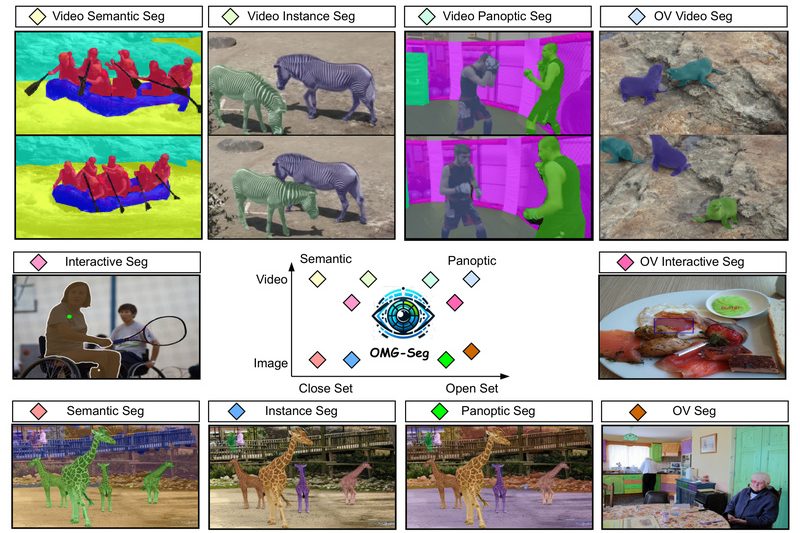
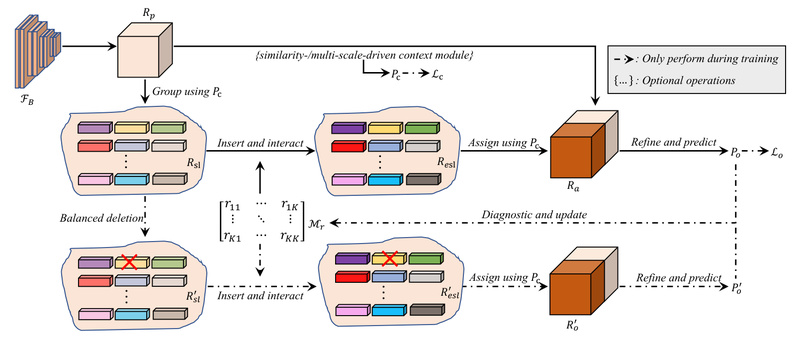
For years, computer vision practitioners have juggled a patchwork of specialized models to tackle different segmentation tasks—semantic, instance, panoptic, video,…
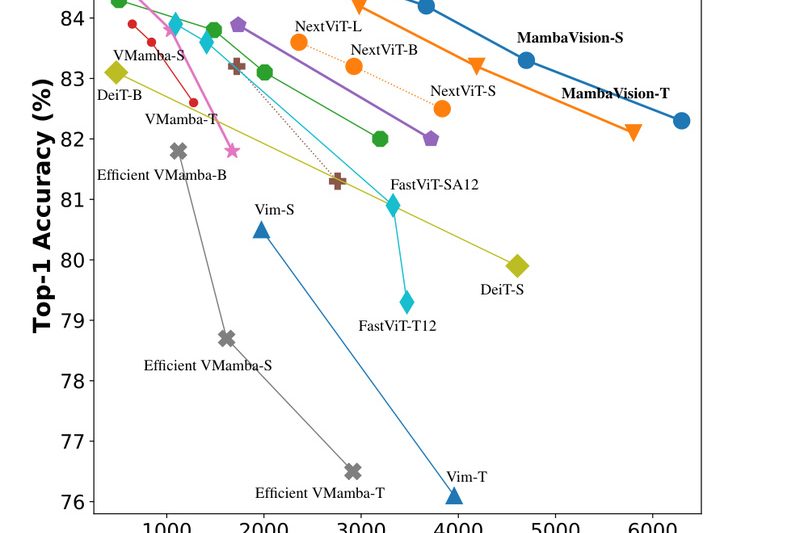
If you’re building computer vision systems that demand both high accuracy and real-world efficiency—without getting bogged down in architectural complexity—MambaVision…
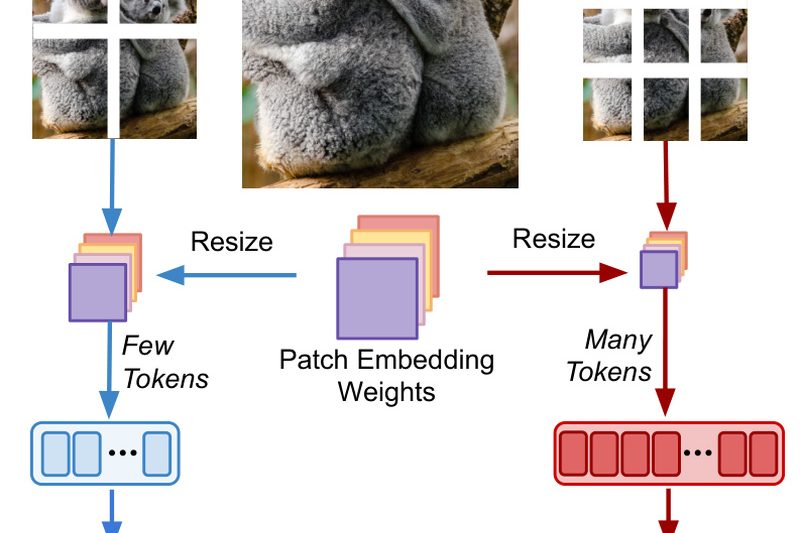
Vision Transformers (ViTs) have become a cornerstone of modern computer vision, offering strong performance across a wide range of tasks.…
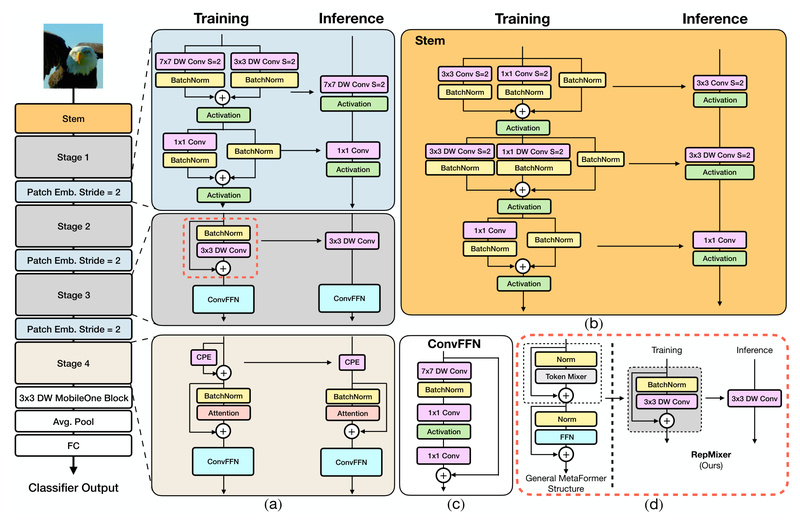
FastViT is a high-performance hybrid vision transformer designed to deliver exceptional speed and accuracy—especially on resource-constrained platforms like mobile phones…
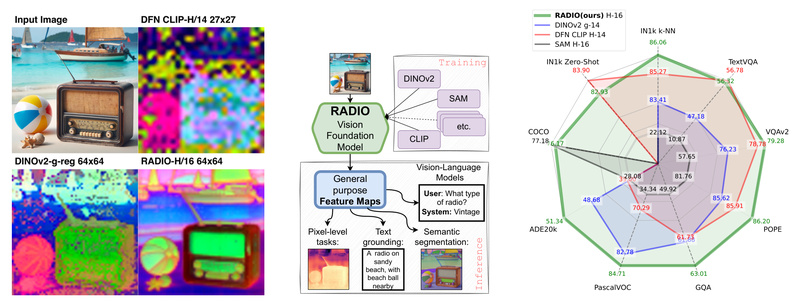
In modern computer vision, practitioners often juggle multiple foundation models—CLIP for vision-language alignment, DINOv2 for dense feature extraction, and SAM…
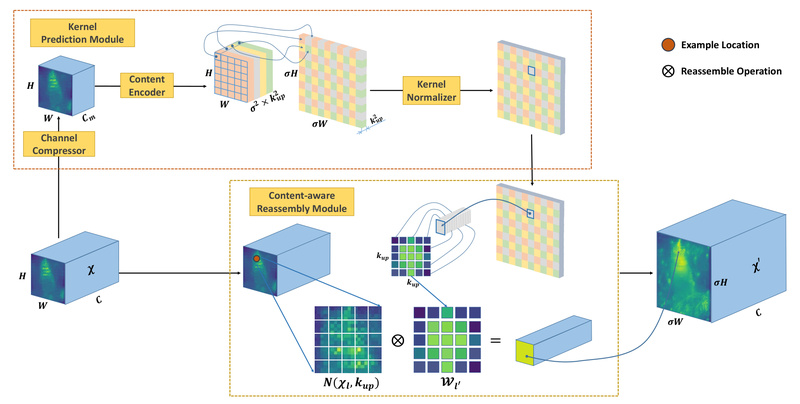
Feature upsampling is a critical but often overlooked component in modern computer vision pipelines. Whether you’re building an object detector,…