Traditional spoken dialogue systems—like those used in virtual assistants or customer service bots—rely on a cascade of disconnected components: voice…
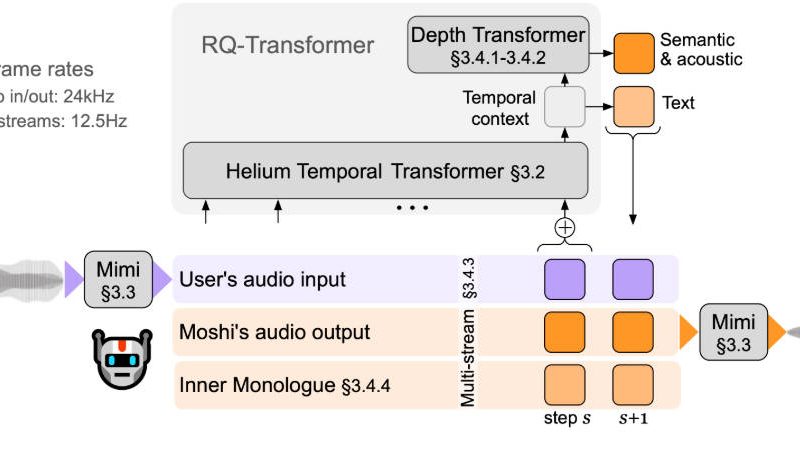
Traditional spoken dialogue systems—like those used in virtual assistants or customer service bots—rely on a cascade of disconnected components: voice…