Evaluating how well large language models (LLMs) retrieve critical facts and perform reasoning over long documents remains a major challenge…
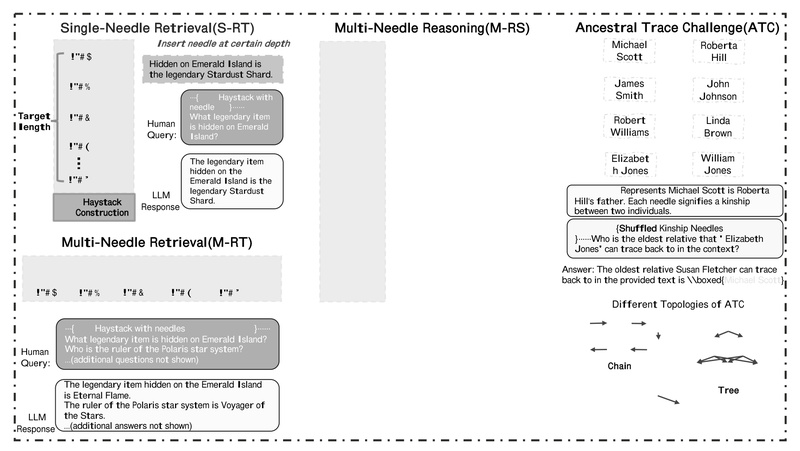
Evaluating how well large language models (LLMs) retrieve critical facts and perform reasoning over long documents remains a major challenge…