Video understanding has long been a bottleneck for multimodal large language models (MLLMs). While models can recognize objects or scenes…
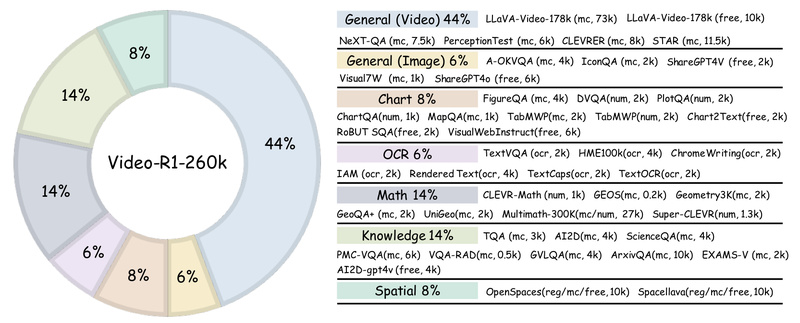
Video understanding has long been a bottleneck for multimodal large language models (MLLMs). While models can recognize objects or scenes…