Large AI models—from language generators to video diffusion systems—are bottlenecked by the attention mechanism, whose computational cost scales quadratically with…

Large AI models—from language generators to video diffusion systems—are bottlenecked by the attention mechanism, whose computational cost scales quadratically with…
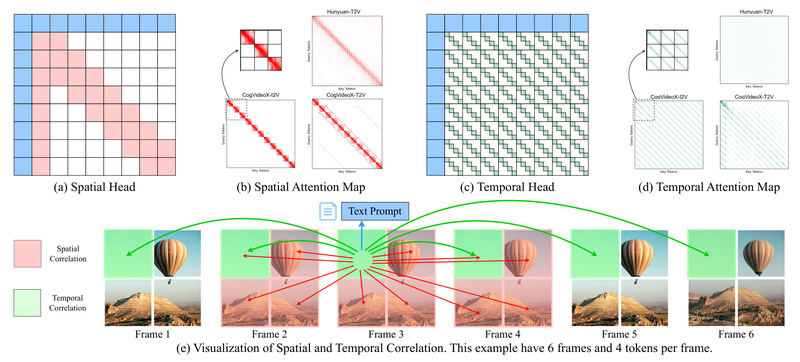
Generating high-fidelity videos with diffusion models has long been bottlenecked by computational inefficiency. Even on powerful GPUs, producing just a…

Video generation using diffusion transformers (DiTs) has reached remarkable visual fidelity—but at a steep computational cost. The quadratic complexity of…

Generating high-quality, long-form videos with diffusion models remains one of the most computationally demanding tasks in generative AI. Standard attention…
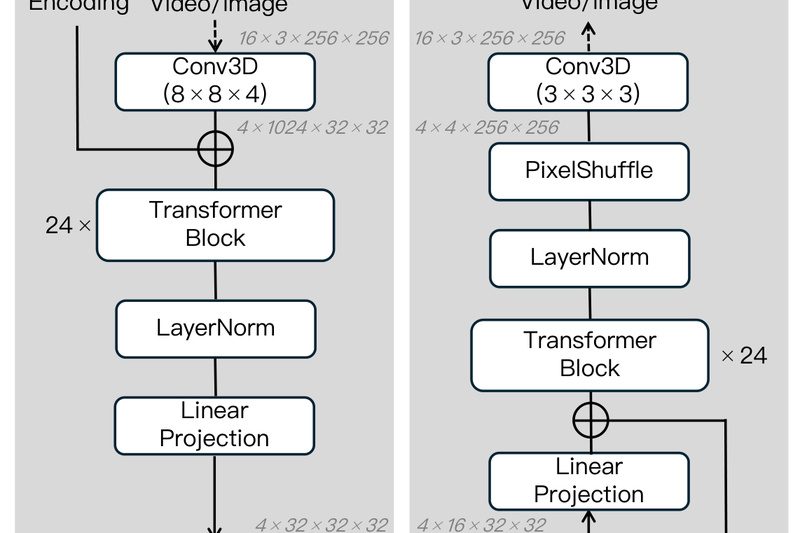
MAGI-1 is a breakthrough world model designed for autoregressive video generation at scale. Unlike conventional video diffusion or transformer-based approaches…

Animating a static human image into a realistic, temporally coherent video used to require massive datasets, complex pipelines, or retraining…
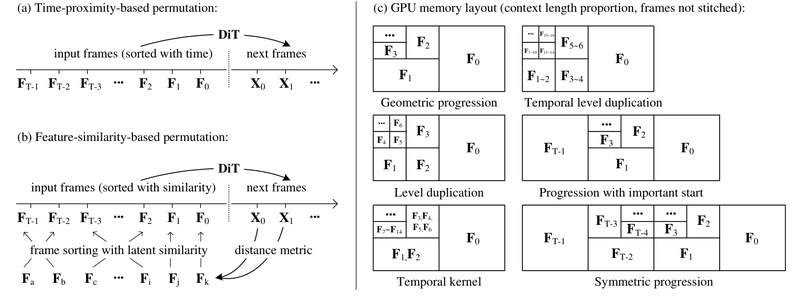
Creating long, coherent, and visually rich videos with AI has long been bottlenecked by computational complexity, memory constraints, and error…

Video generation using diffusion transformers (DiTs) is rapidly advancing—but at a steep computational cost. Full 3D attention in these models…

Creating videos with predictable, controllable motion has long been a major challenge in generative AI. While recent diffusion models produce…

Creating visually coherent sequences of images or videos from text prompts has long been a bottleneck in AI-powered storytelling. While…