Imagine building a vision system that can detect not just pre-defined classes like “car” or “dog,” but any object described…
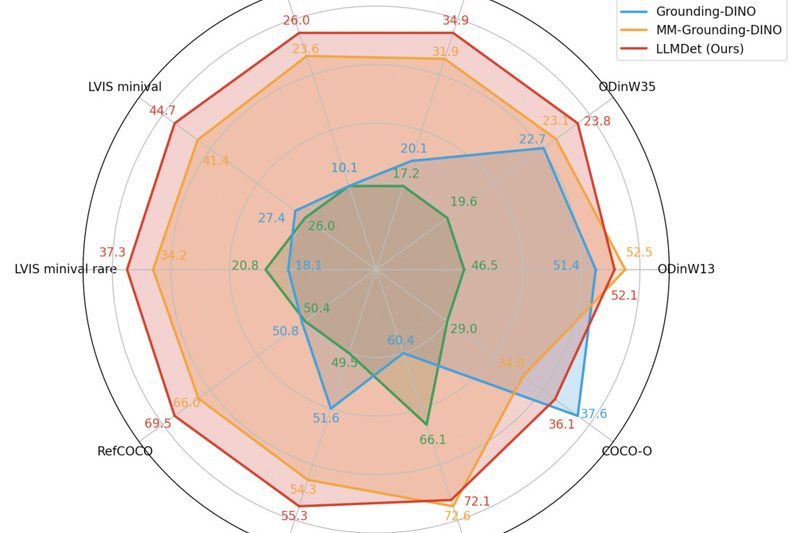
Imagine building a vision system that can detect not just pre-defined classes like “car” or “dog,” but any object described…
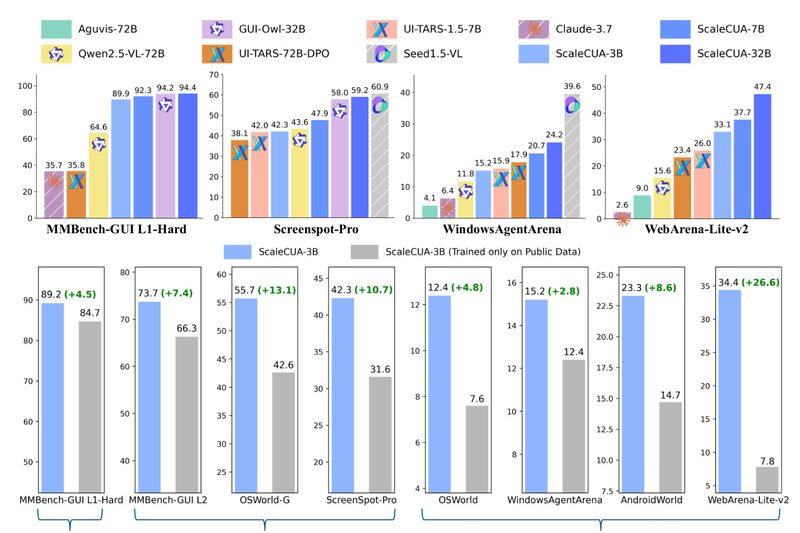
Building reliable computer use agents (CUAs)—systems that can autonomously interact with graphical user interfaces (GUIs)—has long been hindered by a…
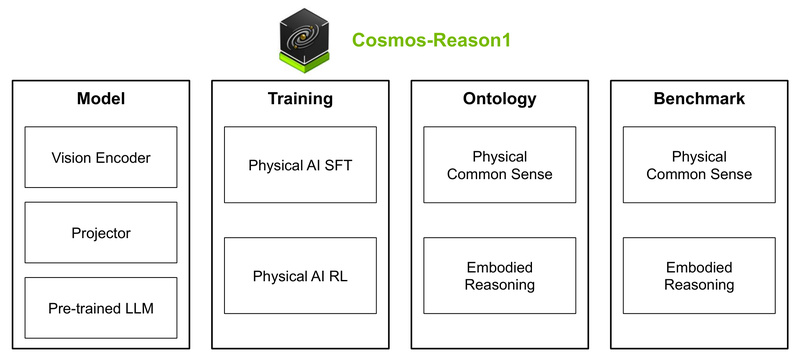
Building intelligent systems that can understand and act in the real physical world remains one of the toughest challenges in…

Most modern Vision-Language Models (VLMs) treat images as static inputs—processed once, then reasoned about using purely text-based logic. But humans…
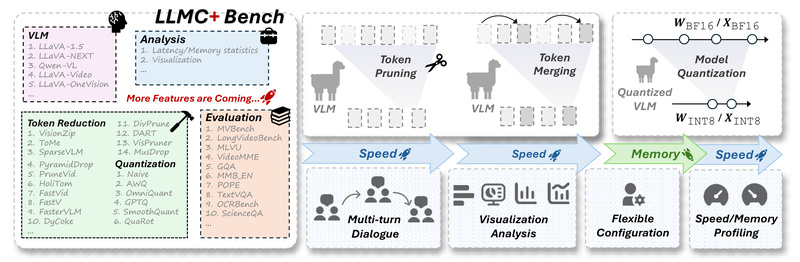
Deploying large vision-language models (VLMs) and large language models (LLMs) in real-world applications is often bottlenecked by their massive size,…
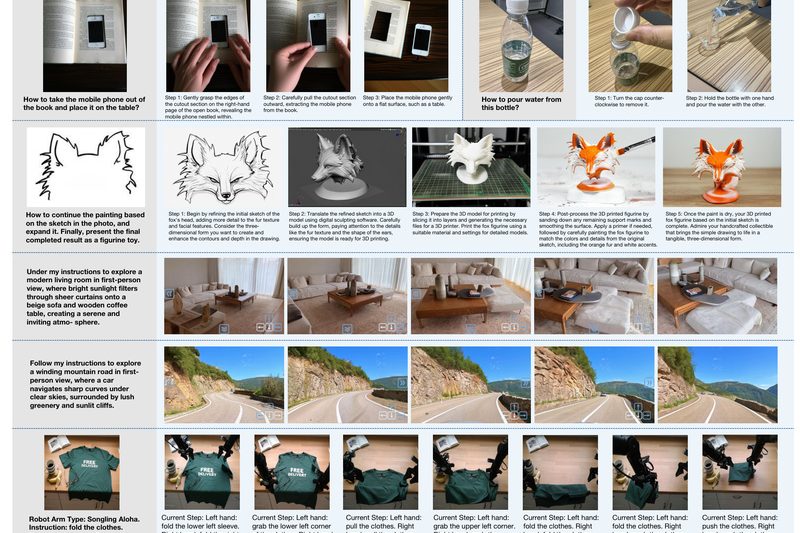
Imagine a single AI model that doesn’t just “see” or “read”—but seamlessly blends images and text in both input and…
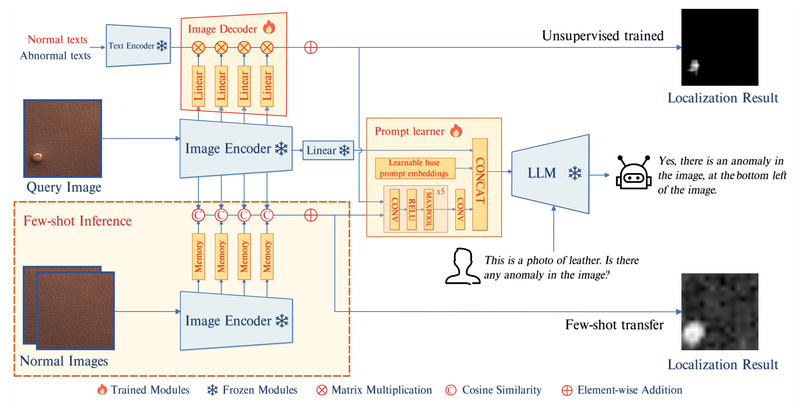
In industrial quality control, detecting defects—like cracks in concrete, scratches on metal, or deformities in packaged goods—is critical. Yet traditional…

In today’s AI landscape, multimodal systems that understand both images and language are no longer a luxury—they’re a necessity. Yet,…

In the rapidly evolving landscape of multimodal artificial intelligence, developers and technical decision-makers need models that go beyond basic image…
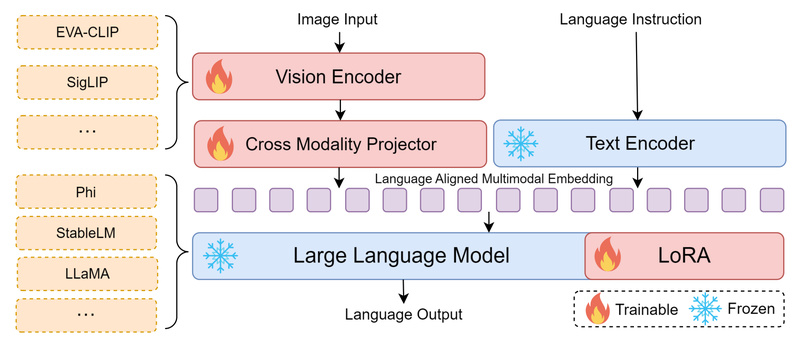
Multimodal Large Language Models (MLLMs) are transforming how machines understand and reason about visual content. Yet, their adoption remains out…