In today’s AI landscape, multimodal systems that understand both images and videos are increasingly essential—but most solutions force you to…
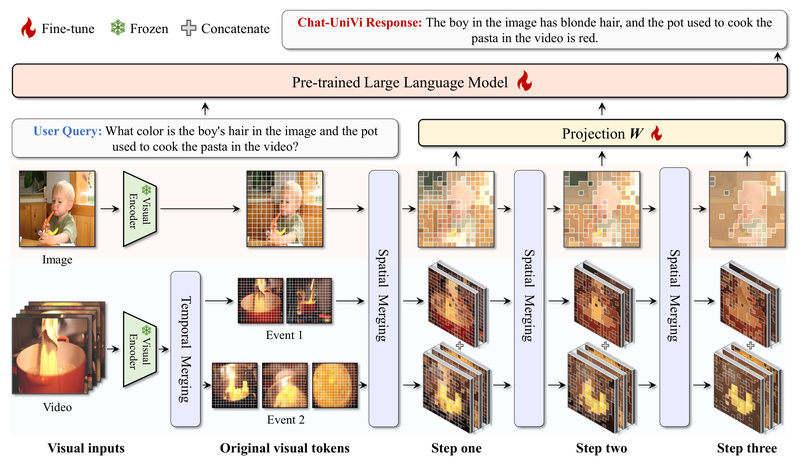
In today’s AI landscape, multimodal systems that understand both images and videos are increasingly essential—but most solutions force you to…

Image segmentation has long been a cornerstone of computer vision—yet traditional approaches often behave like black boxes, especially when faced…

Most modern Vision-Language Models (VLMs) treat images as static inputs—processed once, then reasoned about using purely text-based logic. But humans…