SEED-Voken is an open-source toolkit developed by Tencent ARC that delivers state-of-the-art visual tokenizers tailored for autoregressive visual generation. Built…

SEED-Voken is an open-source toolkit developed by Tencent ARC that delivers state-of-the-art visual tokenizers tailored for autoregressive visual generation. Built…
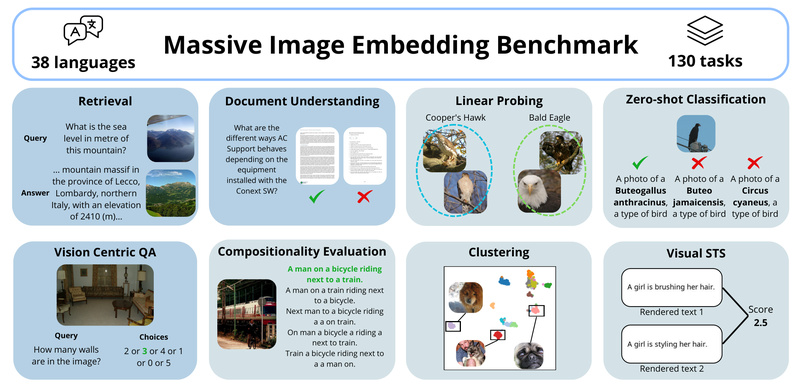
Evaluating image embedding models has long been a fragmented and inconsistent process. Researchers and engineers often test models on narrow,…