What if a single large language model (LLM) could both understand and generate high-quality images—without relying on external vision encoders…
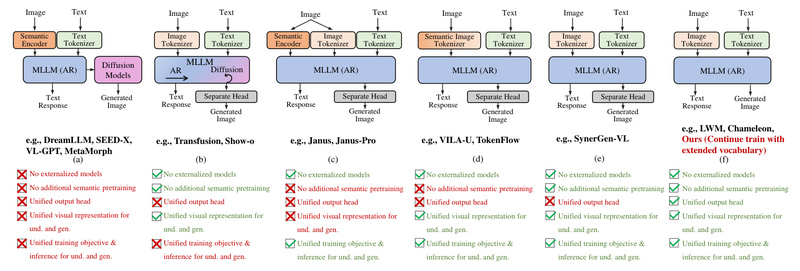
What if a single large language model (LLM) could both understand and generate high-quality images—without relying on external vision encoders…