Multimodal AI models like OpenAI’s CLIP have transformed how developers build systems that understand both images and text. But there’s…

Multimodal AI models like OpenAI’s CLIP have transformed how developers build systems that understand both images and text. But there’s…
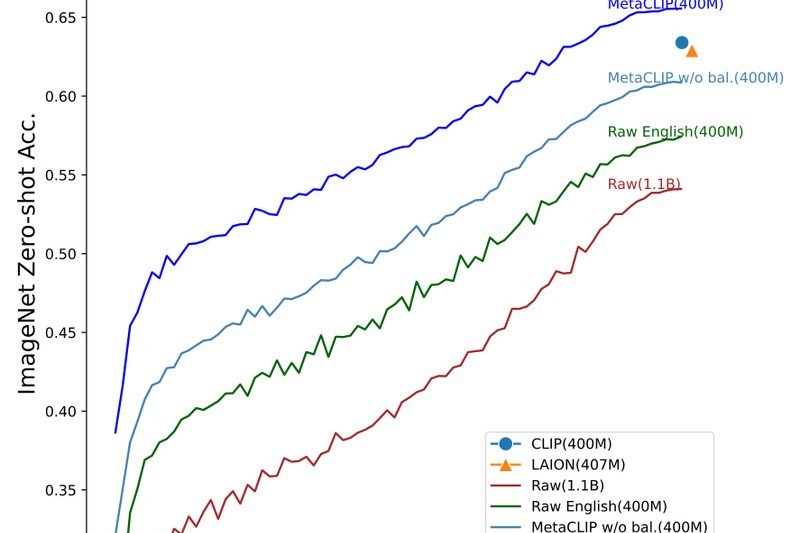
If you’ve worked with OpenAI’s CLIP, you know its power—but also its opacity. CLIP revolutionized zero-shot vision-language understanding, yet it…
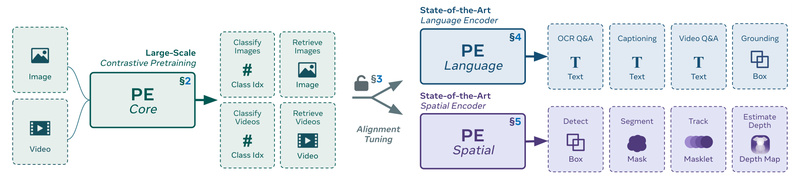
Perception Encoder (PE) redefines what’s possible with a single vision encoder. Unlike legacy approaches that demand different pretraining strategies for…